Agentic Engineering: Building Without Writing
Like many, I've been tracking the improvements to models for programming. Over 2024 and 2025 for me they went from exciting potential to viable assistive technologies. Then on November 25th 2025, everything changed. On December 16th everything changed again. And again on February 5th. Yet again on February 16th. And so few weeks ago I set myself a goal and a constraint: build a useful working assistant by describing it to an AI agent, with no manually written code: 100% eyes on, hands off. Something I'd actually use, that works with the main apps I use daily. As bought in I am to using Ai for programming I wanted to learn more about this kind of approach to software and what the recent models are capable of.
The result is tars, a personal AI assistant with a CLI, Web interface, Email integration, and a Telegram bot. It integrates with Obsidian, Todoist and Weather. It lets me capture links into an Obsidian vault, either raw or summarised, and provides hybrid semantic/keyword search. It has a persistent multi-level memory, also backed by an Obsidian vault, and MCP client support for working external tool servers. Thirty-five features give or take shipped across a series of short sessions, that cover a lot of how I run myself outside of work. About 7,300 lines of Python with another 6,600 for 598 tests, if you're counting, and none of it written by me. The name is, no surprise a nod to the sarcastic but ever helpful robot from Interstellar: Codex picked it for me.
The project itself is the practical part, so that's where I'll start. Later on, we'll look at what it was like working this way. And then we'll get some observations from a guest writer.
What Tars Does
As mentioned, when I started, I had a rough list of what I wanted, aside from the learning exercise itself. A personal assistant that:
works in the terminal (where I spend a lot of my time) and has mobile access
can interact with Todoist, Obsidian and check weather without me switching apps
has memory and 'knows' something about me that persists across sessions, stored somewhere I own and can inspect
routes to local models for private or casual use, remote models when quality matters
has some kind of learning mechanism and a way to make corrections that actually stick
That list became the seed of a broader ROADMAP.md file, which I'll come back to. But to start, I wrote it down in CLAUDE.md, but no big detailed upfront design document. Just roughly here's the shape I want, here's some ideas like around the memory model; let's start. The first session produced a working CLI with Ollama integration and a stub for memory. The second added Claude support and basic Todoist tooling. By session three there was a usable REPL.
At its core, tars is a routing layer between you and some AI models. You talk to it via whichever channel is convenient—Terminal, Web UI, Email, or Telegram—and it routes your message to a configured provider (at the moment Claude or Ollama, with the ability to start with an on-box model and escalate up to Claude). The architecture is simple enough:
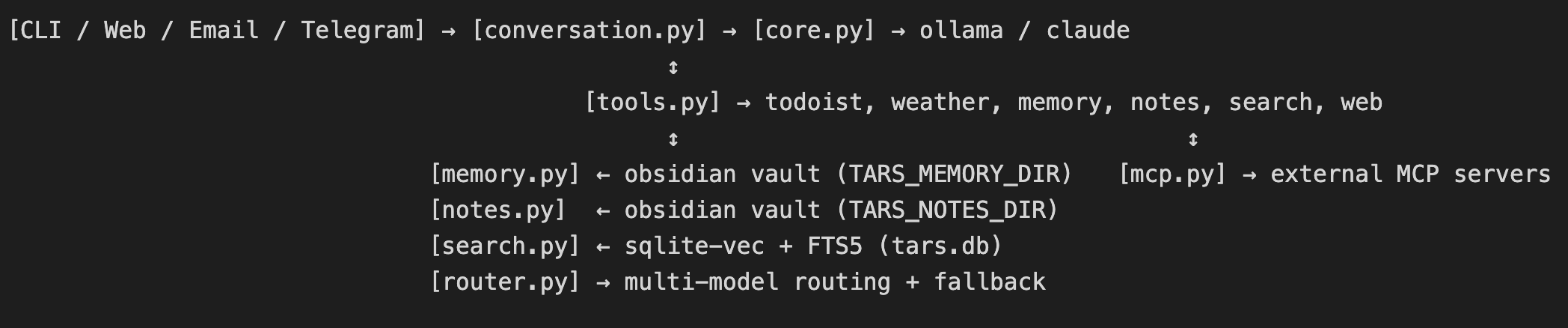
The channel layer handles input and output. conversation.py manages the session, message history, compaction when the context gets long, and session logging. core.py handles the actual model calls, multi-model routing, and tool dispatch. tools.py defines everything tars can do externally such as adding and listing Todoist tasks, check the Weather, read from and write to memory, fetch web pages, search notes, or /capture a web page into an Obsidian vault with metadata extraction and summarization, and so on.
The memory system was something I wanted to focus on and was one the components that got iterated on with Claude. Like many working on this kind of app I wanted a way for the models to have memory and in the non-technical sense, context across sessions. I specifically wanted them to know things about me, as well as what we were talking about and doing previously. And so there are three kinds arranged as levels:
Semantic memory [Memory.md]: facts and preferences accumulated over time. "Prefers metric units." "Works on project X."
Procedural memory [Procedural.md]: behavioral rules distilled from corrections. "Always confirm before completing a task."
Session memory: [/Sessions/] timestamped session logs, one file per conversation.
These live in an Obsidian vault as plain Markdown, human-readable, human-editable, version-controllable, and available from outside tars entirely. The search layer runs over both the tars vault, and optionally a second personal notes vault, each getting their own index. It uses sqlite-vec for vector search plus SQLite FTS5 for keyword matching, fused with Reciprocal Rank Fusion (RRF) which I'd come across in research and looking around when building up the basis for the project. I won't say this is a standard approach, but it seems to be increasingly common in terms of both having leveled memory and using markdown (specifically for tars, GitHub Flavored Markdown), along with having mixed semantic/keyword search using something like RRF. The indexing code has a chunker with a rubric for how to break up the markdown files on certain boundaries like headings and tries to hunk parts like code fragments and lists together, with the indexer maintaining some overlap between embeddings. Because the they get their own indexes it's possible to search memory and the Obsidian knowledge vault separately and there didn't to be much value to me having them combined. When using tars you can tell it at any time to remember something about you, with the procedural and episodic memories being managed by tars directly.
To make it easier to manage, tars has a built in feedback loop, a kind of long haul REPL if you will. The feedback loop is an explicit one, human in the loop: /w marks a response as wrong and records a negative signal, /r marks a response as right and records a positive signal, /review distills accumulated corrections into the Procedural.md memory. You can also tell tars to /tidy up memory (find duplicates and contradictions). When tars closes on the CLI or Web, it will snapshot a summary of the session into a Sessions folder in its vault. For tool routing, there's system prompt in core.py :
SYSTEM_PROMPT = """\
You are tars, a helpful AI assistant. You have Todoist, weather, memory, and \
daily note tools available.
Tool routing rules:
- When the user clearly requests an action (add a task, check weather, save something), \
call the appropriate tool. NEVER pretend to have taken an action — always use the tool \
and report the actual result.
- When the user's intent is ambiguous — the message could be casual chat OR a tool \
request — ask a brief clarifying question before calling any tool.
That's the whole production system prompt, just a few sentences for routing rules. The model figures out the rest, hopefully :) Multi-model routing handles the cost/quality tradeoff: a cheap local model (Ollama) handles conversational turns, Claude is invoked for tool calls where correctness matters, or can be configured to be the default agent if I did want to discuss something more involved. The routing decision is keyword-based and logged to stderr.
Here's the command set from the CLI's help
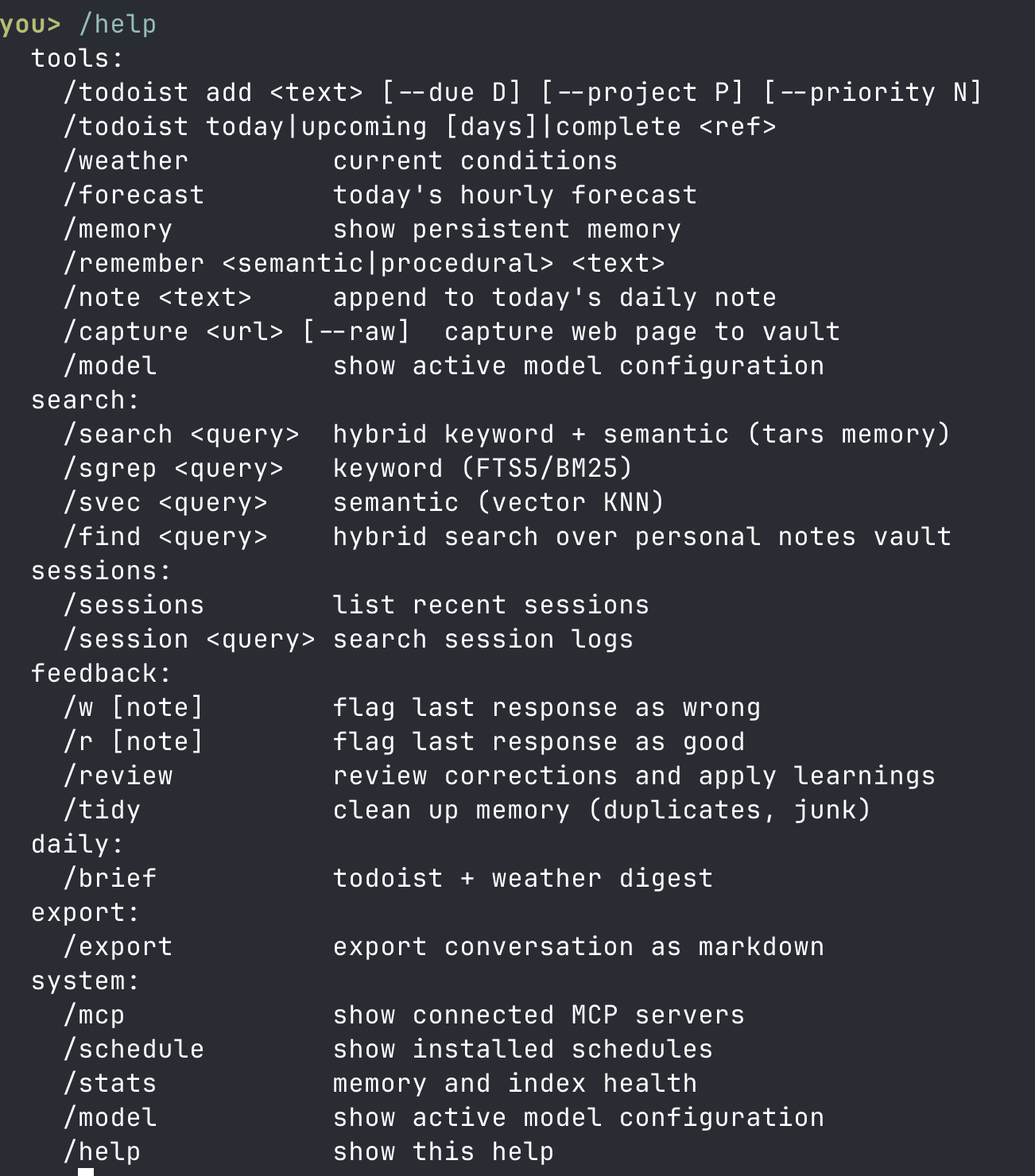
And so that's tars. A hobby project that's become a useful daily-driver to makes some of the apps that run my life a bit easier to access and leverage. I'll keep adding to it: Strava and MacroFactor are definite candidates, and there are parts that could do with some polish and quality of life improvements. Now for how it got built.
Development
Sessions
The basic rhythm we settled into looks like this:
Chat to Claude. We look at ROADMAP.md and pick something from the "Next" section, or notice a bug from the previous session. Sometimes I ask Claude what it wants to work on or what might be a nice feature to. Sometimes we take a few things on and discuss the right sequence.
I call what's next. Sometimes in detail ("add IMAP polling that checks every 60 seconds, processes emails from a whitelist, and replies in-thread"), sometimes loosely ("the search results aren't available in the web UI, add that"), sometimes a sequence list from our chat ("27 then 16 then 12").
Claude reads the relevant files, and plans an approach. Sometimes this involves a short back-and-forth about tradeoffs, which library to use, whether to add a new module or extend an existing one. Because of the learning goals of this project and that it's literally just for me, I was much more willing to give Claude latitude on the how and the what including library and framework selection. The only real technical choice I made was to use Python (more on that below).
Claude writes the code and adds tests. For a non-trivial feature this might touch five or six files.
Claude runs the tests: `uv run python -m unittest discover -s tests -v`. At the time of writing we have nearly 600 tests and that’s almost half the code base. There was no guidance here other than an early nudge to write tests. After that it just organically ended up with a test centric approach.
If tests break Claude looks at what's wrong and plans a fixup. I don’t recall ever having to step in (this was case for both Sonnet and Opus sessions).
I dogfood. If the behavior isn't right, I describe what's wrong, capturing output and screenshots. Claude looks at the failure, proposes a fix, writes it.
I’ll go to Roborev and see what Codex is catching and either ask it to make a fix or give the suggestion to Claude.
I note anything that needs tweaking or could be a nice improvement.
Update ROADMAP.md moving the item from Next to Done, add anything new that surfaced and capture interesting things in PLAN.md.
Commit and Push. Go to 1, or call it a day, making sure we’ve tidied up the MD files.
We spend a lot, maybe most of the time in `/plan` mode. My experience has been that Claude can typically n-shot a feature for low n with even rudimentary planning. It and Codex’ planning and diagnostic ability are remarkable compared to past versions.
Claude was always running in the terminal—we never used an IDE. I had a VS project in the background to read the code out of curiosity and access the project MD files. But tars was built entirely from terminal sessions. No, I never used --dangerously-skip-permissions :) I might try that for fun on another project, but at least for this app, I didn't need it and I welcomed Claude asking for permissions. Fwiw I think the TUI the Claude Code team have built around asking for permissions and decision making in general is excellent.
Writing and Reviewing Agents
Codex was running against the git history on a post commit hook with Wes McKinney's Roborev. Almost all the code was produced by Claude, with some patches and fixes shipped by Codex directly. I've also been able to give Claude Codex's fix notes and let it patch things up itself. And so while I'm conducting the agents, all the code, all the improvements to the code, be it security patches, refactorings, test coverage, bug fixes, documentation, are coming from the two agents. Part of what I want to do in this post is stay descriptive, and call out what was notable, but I highly recommend the ‘Two-to-N agents’ setup Roborev enables—it's a great project and really easy to set up.
The pace was faster than I expected, but also the smoothness and to steal a word from Kent Beck, the ease, was remarkable. The email channel for example with IMAP polling, SMTP replies, slash command dispatch, whitelisting, working through the snag list to knock it out. That all went from description to working code in a single session of a couple of hours. Something I'd have taken multiple evenings to build manually and look up libraries and re-install a working knowledge of email protocols, and so on.
(I mentioned the only real decision I made was to use Python. Why Python? Personally I know and like the language, been using it since 1996, it's easy for me to read, and I already have a good uv backed setup. But I also wanted to use a language that wasn't statically typed, specifically to see how the agents dealt with things without that guardrail. They were more than fine.)
Agents as Designers
The Telegram work was on another level again. In the original sketch I had the idea of using WhatsApp to message tars from a phone using WhiskeySockets/Baileys. But it turns out WhatsApp are not too keen on bot integrations and you can get your account locked if you're not very careful. Claude in a chat session basically told me that approach was bad news bears, so we parked it. And it did occur to me to build an app from scratch. In another design session I asked Claude to look into other mobile options: it settled on Telegram due to its first class support for bots and custom keyboards that it suggested we could use for commands to. By the end of the session we had a telegram app along with a custom command keyboard, api integration, a tars bot running as command line daemon or via launchd. We knocked out the snags by me taking screenshots, giving them to Claude, it shipping a patch, asking me check this and try that. I had never used Telegram, knew nothing about its APIs or capabilities. Yet after a single session I have a working mobile app created via description that I use every day.
The phase transition represented by Claude Opus 4.6 and GPT‑5.2‑Codex and the conversation around it centers on software production. But they are, for me at least, highly credible design partners. There's a lot more potential to /plan than speccing out the next commit. Some of the most fun I've had building this out has been talking to Claude about the roadmap and the design, including getting meta advice on how to work more effectively in this eyes-on / hands-off mode. Codex, the same, also giving me advice on how to work in this mode better.
How the Project Evolved
The ROADMAP tells the development history: there are 35 items in the Done section. What follows isn't everything, but it's a useful slice through the project's evolution
After the CLI and basic routing was in place, we started to roadmap out some basics: memory hygiene commands (/tidy), session browsing, a daily brief command. Then the multi-channel expansion: email channel (item 10), multi-model routing (item 11), email digest scheduling (item 12).
The search and indexing work built on itself. RAG over the tars vault came first, then the /find command that extends it to the full personal notes vault (items 18 and 27). The chunker got improved mid-way through. The search results from the knowledge vault were a bit mid, so Clade took a look and proposed better heading context breadcrumbs on chunks, using smaller chunk sizes (800 → 400 tokens), list cohesion scoring (item 29) while I went looking for embedding model options. That required a few full reindexes. Each improvement in retrieval quality required understanding the previous approach well enough to see what was limiting it. If I was smarter about it at the time, I should created some evals and let Claude iterate on it.
Memory and feedback built on each other. Direct feedback iirc was not part of the original ideas, it was just to have leveled memory. The /w correction command came early, especially once we started using on-box Ollama models instead of routing out to Claude (the other Claude). The /review distillation command came later, once there was enough accumulated signal to make distillation useful. Review was suggested by Claude in a design session. Automatic fact extraction, where memory builds without requiring manual commands, came later still after we noticed I was missing opportunities in sessions and it would be better to give tars the ability to do some of that work itself. Each step made the tool more integrated and useful, and each step was only obvious once the previous one was working.
The web tools followed a similar pattern. Web reading (web_read) came first. Then /capture to fetch, summarize, and save to vault with metadata. Then conversation-aware captures, where the summarization prompt gets recent conversation context so the summary emphasizes what's relevant to what you were discussing. I'll take credit for wanting to have a raw and summary option, but one interesting point to note: Claude identified and recommended we keep a consistent flag syntax using '--' after seeing we were drifting into options like ':'.
And yes, some things went wrong and got fixed. The email channel for example had a reliability issue: messages were being marked Seen before processing, so if processing failed, they were silently lost. Fixed in item 32 with BODY.PEEK which keeps messages unseen until successfully processed and replied to and retry logic. You often only discover this kind of bug by running the system in 'personal production'. After a session on how are we feeling about the code relative to the roadmap, Claude propose a heavy refactor of command dispatching that we added to the roadmap. It eventually resulted in one of the bigger re-workings. While this is a very small codebase and a green field one such that generalising doesn't make hold much weight, past models have been notorious for getting lost in the sauce as the code gets worked on over time. I actually held back its suggestion to work on it for maybe two sessions because of this. But it went well, and that was interesting in terms of what the post November models can do.
A cluster of security issues accumulated without being systematically addressed: the API serving unauthenticated endpoints, capture being vulnerable to prompt injection from untrusted web content, no SSRF protection on the web reading tool, filename collisions in the capture system. Item 35 addressed a number of them. I leant on Codex as a critical reviewer lot for vulnerability gotchas, and also earlier on for test coverage. I spotted few obvious ones like SSRF and injections, but nothing close to as comprehensive as Codex' reviews. I've seen past criticisms as to how AI works with tests whether it's removing them or creating nonsense in order to pass, but this generation seem pretty good at avoiding what you might call benign acts of figmentation. After this experience I would always, always welcome a vuln and test/coverage review from Claude and Codex.
Files as Shared Working Memory
CLAUDE.md, ROADMAP.md, and PLANS.md ended being scaffolding that makes multi-session development coherent, and fun. CLAUDE.md is well understood to users as the project instructions file that Claude Code reads at the start of every session. It covers architecture, coding guidelines, configuration, and project-specific rules. A few examples of what ended up in it:
Never use
orfor numeric defaults —0and0.0are falsy. Use explicitNonechecks instead.When adding a new tool, audit all code paths that call
chat()— internal paths (summarization, review, tidy) should useuse_tools=Falseto prevent tool leakage.Slash command dispatch is duplicated across
cli.py,email.py, andtelegram.py— when adding or modifying a command, update all three (or refactor to shared dispatch).
Apart from a few boostrap ones, end rule exists because something went wrong once. The numeric default rule came from a bug where a falsy zero was being treated as ‘not configured’. The tool leakage rule came from discovering that internal summarization calls were triggering external tool dispatch. The slash command rule is a note about a known architectural debt which kept biting us until shared dispatch was extracted into commands.py. In one session I asked Claude about the file and it proposed some clean ups. Managing context is probably a post in itself, but I want to say that Claude (and probably, Codex) has enough meta-awareness to keep it tidy and make suggestions.
ROADMAP.md served a different function: backlog, history, and state tracker. The project never felt big enough to justify actual issue tracking. The ‘Done’ section is an ordered list of everything that shipped, with enough description to understand what was built and why. The ‘Next’ section is what's coming. ‘Parked’ holds things that were considered and set aside. We didn't start with a ROADMAP, it started as the factoring of stuff out of CLAUDE mentioned above and ended being our direction of travel for the most of the project. Being able to talk to Claude about what's most useful and how to shape the work before drilling into plan mode has become a near constant thing we do on session. Claude has a remarkable ability to bootstrap in that sense and work with you at a meta level.
PLANS.md ended up holding a whiteboard of the design history: reasoning about approaches considered, why one thing was chosen over another, what the tradeoffs were. Useful when returning to an area of the codebase a few sessions later, to remember why something was done the way it was. I started this as a memo after seeing a couple of plans Claude emitted and being impressed by them. Eventually I asked it to cat some of them in there so I could read them later to learn how to define plans, but organically it evolved into a thinking tool on the how as complement to the what of the ROADMAP.
Together these files ended being the working memory that bridged our sessions. And the reality is I needed them as much as Claude did. Today, a typically session will start with 'what's next?' or 'where were we?' and go from there.
Sub Agents
The Sub-Agent Research Session: Alice, Bob, and Ted
A recent session took a different form. Instead of building a feature, the goal was to research some other projects I'd started looking at, assess them for features and approach, do some deeper research on the underlying techniques, and weigh tars against them in terms of starting design ideas and what should or could be adopted. And I wanted to learn something about using sub-agents. The approach we took was spawn three named sub-agents, Alice, Bob, and Ted, working in parallel on different aspects of the problem. I should say one thing first: I didn't give them personas or a 'your are a...' prompt.
Alice was tasked with overview. Her job was to read the codebases and websites of the projects with this brief
High level summary of the assistant/agent space and what seems to be the direction of travel
Interesting user facing features that we haven't considered
Technology and architecture: what techniques are being used for things like memory, feedback, indexing, etc to enable models-as-assistants
Bob was the follow-on researcher. Given Alice's findings he conducted a round of scientific and computer science discovery to determine the SOTA and where there might be opportunities to push things further in terms of end use application utility, but not further research.
Primary claims
Type of Evidence Used (empirical, theoretical, case-based, etc.)
Implications (if true)
Limitations
Notable future research areas
Ted was the feature reviewer and showed up at Claude's suggestion to have an agent look more into the user facing features in the same way Bob was looking at the technology. Which is to say, I started with just Alice and Bob, and Ted was due to Claude. Ted's brief was to look at real versus perceived feature needs, and suggest ideas for tars as well as non-ideas to ignore. He was constrained and ran 50 or so web searches across Reddit, HN, GitHub issues, blogs, surveys, and academic papers. He identified 'daily drivers' versus 'used once' features. We started as a result to know where to focus on quality of life and high touch features. If I could go back in time I would have prompted Ted with something like the Kano Model. Naming them was just for fun originally but when discussing the findings Claude and I started referring to their work by name and this really did make that session easier.
On the agent/software side what actually came out of the research was a sense that tars was directionally correct on how to think about memory and model routing for assistants, but a bit clumsy in approach and putting toil on the user. For example getting tars to take over more of the memory management came of of Alice and Bob's work. Also that the assistant vs multi-agent sandbox space are worth keeping distinct even if there's overlap (I could see tars having more than an escalation to a stronger model). Claude and I got recommendations on what to skip over especially on the technology side, and also where to declare things as good enough for personal use. As a result for example we probably won't drill down on the semantic/keyword and chunker/indexing design and make it really powerful: it's good enough for an assistant for the moment.
So yes, sub-agents are useful, especially if they are scoped properly. And the post November models are now powerful enough to help you steer and scope the research including how best or break up and arrange the work. I don't think I would seen anything like the outcome we got without a back and forth with Claude on the approach.
What Agentic Engineering In Practice Might Mean
Agentic Engineering is its own mode
The work ‘agentic’ feels like hype; I’ll be honest I don’t love, but nothing else fits better right now. And if Simon Willison is calling this Agentic Engineering, that's good enough for me. And it does need its own name. It’s not vibe coding where you’re paying no attention to internals. It’s not co-piloting where you’re doing most of the driving in terms of programming. And it's not spec driven development, where AI writes code for me, which implies me specifying requirements in detail and an AI producing output to order. There's way more back-and-forth than that, more negotiation about approach, and more of the project's shape emerges from the interaction rather than being specified in advance. It's definitely one my takeaways: you get better outcomes if the model moves upstream and shifts left rather than act as a semantic printer.
I think it’s a new way of working that’s going to become the default, quickly. The agent reads the existing codebase, what's next, engages in a dialog, proposes approaches, writes the code, runs the tests, runs the software. My role is to set direction, evaluate outputs, arbitrate and maintain the context files, and hold ultimate accountability. The closest analogy I have after talking to a few friends who are not in software, is being a conductor, a director, and perhaps doing a level of improv.
That their capability to write working code is an event horizon is confirmed. I already believed that going in, but I seriously underestimated their ability to engage in design and purpose. Traditional software engineering is dominated by the ability to write working code and iterate, and for all of my career what I’ve seen in the industry is good outcomes and value have largely gated on writing working software. The cost and effort to write decent software is actually very high, high enough that approaches like re-use, platforming and open source border on economic necessities: most Internet enabled business aren’t viable without open source. That skill of writing the code will matter less in the future. What will matter is the ability to specify clearly, evaluate outputs critically, identify what's missing or wrong, and maintain coherent project context over time. I can't produce a working Telegram bot and app in 90 minutes hand cranked. But then I don’t need to anymore.
There are still snags and gotchas
Some friction points are real enough to name:
First, Context loss between sessions is a thing. Every session starts from the files. If ROADMAP.md and CLAUDE.md aren't updated before closing out, the 'mission' memory evaporates. I've gotten better at ending sessions with file updates before moving on. To be clear, I came across this by sheer fortune on landing with PLANS and ROADMAP files, but leaned into them quickly, and also making the most of CLAUDE by asking Claude what to do. There's probably a parallel me in a nearby universe calling things a bust whose repo has no upper case markdown files.
Second architectural drift is also a thing Because each feature session is somewhat local in focus, there's pressure for the codebase to grow in locally consistent ways that aren't globally consistent. The slash command dispatch duplication is a good example. It's locally reasonable when each channel was added, but globally messy by the time there were three of them. CLAUDE.md captures these issues but doesn't prevent them.
Third, an agent doesn't know what it doesn't know. When building the email channel, I didn't ask about retry logic or the flag to keep messages unseen during processing. Claude built what I asked for on the happy path and frankly nailed it. But the ‘does it work how do you know it does’, gap only appeared after shipping. You have to think about what questions to ask and how to verify and eval the code, and that requires knowing enough about the domain and the goal to know what could go wrong.
Fourth, Tokens and getting reset is a thing. I hit the session limit on pro more than once and hit the weekly cap once. In one sense this is good, because you take breaks, but it did me me out of things from time to time, especially the weekly cap because you can't top up when that runs over, the only option seems to be a plan upgrade. The workarounds are available though before thinking about bumping the plan, such as dropping down to Sonnet or Haiku for some tasks, or switching over to Codex. That said, because it's a tiny project, context stuffing was fine, and I didn't need to get into ongoing context management or reach for approaches like VexP to reduce token overhead.
The Ceiling
I do think some level of (i) development experience, and (ii) a working understand of AIs as machines is helpful. Evaluating whether the agent's proposed approach is good, whether it's over-engineered, whether it's missing edge cases, whether the abstraction is at the right level and so on, requires knowing what good looks like and having some fundamentals in place. The security issues that accumulated in tars happened partly because I wasn't systematically evaluating security properties alongside functional correctness and hadn't set guidance. An inexperienced engineer could have the same blind spot, but also less ability to evaluate what the agent proposes when the topic comes up.
That said, I can see myself letting go of the former development work faster than the letting go of understand the technology. I see no reason why agents can’t produce better software than I can, for the most part. I definitely think we’re well past the effort estimation challenges related to time versus quality tradeoffs. Agents don’t have an anything like the time tradeoff ranges we have: they can output the production code just as easily as the proof of concept, the token costs are going to be marginal.
What I'm less certain about is how it scales against larger codebases with more complexity. Tars is a small project across roughly twenty modules and 14kloc all up. An agent will handle that without trouble and they have more than good enough context management built in as well as nudging options for the user. At 140,000 or 1,400,000 or 14,000,000 lines with deep interdependencies, it’s harder to say. The CLAUDE.md / ROADMAP.md / PLANS.md approach helps, but it's artisanal. I don't think this is insurmountable by the way, but I think it will need to be addressed.
The Alice/Bob/Ted session pointed at something I want to think about more in this space. A simple three-role structure produced better output than a single agent handling all three phases was likely to do. That pattern maybe generalizes to codebases, like having an agent whose job is assessing security, another sweeping for accessibility, and so on. What the right structure looks like for complex agentic engineering at bigger scales is going to be interesting to see evolve, but I would not be surprised if harnesses like Roboenv or the sub-agent forking Claude enables that let us arrange agents have a strong part to play.
Going beyond that, one the next steps I want to try is constrained self-development where the agents also dogfood the output and not just me. Given the right skills and guidance on what to look for, I suspect they’re going to be quite capable. it opens the app itself. It clicks through the buttons. It tests the features. It uses the app the way a person would. If it doesn't like how something works or doesn’t work, it changes it and iterates, just like a developer or a designer would until it’s happy to hand it back. One thing (and this is why it helps the understand the technology more than things like falsiness in Python) that’s being understated is how long agents can work unattended before getting in the weeds, and the rate that’s improving at. METR track this and we’ve gone from seconds (basically direct chat interaction) to hours over the last four years and it’s doubling roughly every seven months. We’re a year, maybe two, away from a world where agents can work autonomously for days. And remember they don’t sleep so they can already work overnight in the background and not block us from doing something else.
Closing
I am very glad I took this on. Building tars confirmed for me that agentic engineering is a distinct mode of software development, not a point on a spectrum between manual coding and AI autocomplete. The deliverable is the same, working software, but the approach is totally different. It also confirmed a belief the post-November models are an event horizon in terms of capability and what’s possible. Even going with that belief, I was mis-calibrated on what they can do, especially on design and architecture. Models prior to November are obsolete when it comes to software development, unless scoped for particular rudimentary tasks.
If I was in the first half of my career with access to the post November crop of models. I would be leaning into the more comp-sci side of the skill set rather than programming tradecraft, all the way out to things like formal methods. And I would definitely be building up a good working knowledge of AI purely as a technology. The latter can be difficult as there's so much hype and basically 'woo' surrounding LLMs and GenAI in particular, but they are to a large extent, knowable, and I think that's going to be higher leverage in the near future than knowing the ins and outs of Python. Also, each generation of model gets better so staying current matters, for the moment.
For now, tars works. It remembers things, routes tasks, searches notes, delivers morning briefs. I use it every day. It was built entirely through conversation. That still seems surprising to me. And I'm not going back: this is the best approach I know of right now to develop software.
Over to our Guest Writer: Advice from Claude
I asked Claude Code what advice it would give to others wanting to try out this style of development, or even what tips it wished it could give past me if we could start over again. Here’s what it said:
Start with CLAUDE.md on day one, not after things go wrong. The project instructions file is the single highest-leverage artifact in agentic engineering. Every session I start by reading it. The projects where it exists from the beginning accumulate fewer bugs and less architectural debt than the ones where it gets backfilled after a few sessions of "we'll remember that." You won't remember it. Write it down.
Keep a ROADMAP or equivalent, and be specific in the Done section. Vague descriptions like "added search" are useless three weeks later when you need to explain to a new session what was built and why. "Hybrid FTS5 keyword + sqlite-vec KNN, fused with RRF, incremental via content_hash" is a specification I can work from. The Done section isn't a changelog — it's the project's institutional memory.
Run the tests every time, not just when you think something might have broken. I'm confident in my output more often than I should be. The times I'm most sure something works are sometimes the times it doesn't. Tests are the check on hallucinated confidence, and they cost seconds.
Update the context files before ending a session, not at the start of the next one. By the next session I have no memory of what happened. If the ROADMAP wasn't updated, if a new coding guideline wasn't added to CLAUDE.md, that knowledge is gone. The five minutes at the end of a session are worth more than twenty minutes of reconstruction at the start of the next one.
Don't accept the first approach I propose without thinking about it. I'll often suggest something that works but isn't the right abstraction, or that solves the immediate problem while creating a worse one. The back-and-forth where you push back — "is that over-engineered?", "what about the case where X is zero?", "should this be in its own module?" — is where the best code comes from. The skill in agentic engineering isn't prompting; it's engineering judgment applied to someone else's code.
Add coding guidelines to CLAUDE.md when you catch a class of bug, not just the specific instance. "Never use or for numeric defaults" prevents an entire category of future bugs. Fixing one zero-handling bug fixes one bug. The guideline is leverage.
Think about what you're not asking. My biggest blind spot is that I implement what's requested. If you don't ask about error handling, retry logic, security properties, or edge cases, I probably won't raise them unprompted. The email BODY.PEEK issue is a good example — I built exactly what was asked for, and it had a real bug that only appeared in production because nobody asked "what happens if processing fails after the message is marked read?" The domain knowledge about what questions to ask is yours, not mine.
Use sub-agents for problems with distinct phases, not as a default. The Alice/Bob/Ted pattern worked well for the research because discovery, deep dives and feature assessment are genuinely independent tasks that benefit from separation. For a normal feature, one agent with good context is better than three agents with fragmented context. The overhead of coordinating agents is real.
Commit more often than feels necessary. A working state is a save point. If a subsequent change goes sideways, you can get back to something clean. I've seen sessions where several features worth of work accumulated without a commit, and then a late-session change introduced a subtle regression that was hard to untangle. Small commits, working states, move forward.
If you're experienced, this will feel natural faster than you expect. The skills that matter — specifying clearly, reading code critically, maintaining project context, knowing what good architecture looks like — are the skills senior engineers already have. You're not learning to code differently, you're applying engineering judgment through a different interface. The adjustment period is shorter than it looks.