Policywerk: From Tables to Imagination
Policywerk builds reinforcement learning from scratch in plain Python, standard library only, no NumPy, no PyTorch. The sole exception is matplotlib for visualization.
Part 1 ended with a table with 192 entries, one per state-action pair, updated by a single rule. That post covered four foundational algorithms from 1957 to 1989: Bellman's value iteration, Barto and Sutton's actor-critic, TD learning, and Q-learning. Each one solved a problem the previous could not, and each one ran on small discrete environments where every state could be inspected directly. By then much of what is fundamental in reinforcement learning was in place—value functions, policies, temporal difference errors, the tension between exploration and exploitation, actors and critics. Everything except scale.
The three lessons in this post cross that boundary. A neural network replaces the table. A probability distribution replaces the best value. An imagined world model replaces the real environment. Each step is a departure from what came before, and each one is built the same way: scalar operations composed into building blocks, no frameworks.
Three Lessons, Three Missing Pieces
Mnih et al., 2013—Playing Atari with Deep Reinforcement Learning

The environment: Mini Breakout. An 8x10 grid with 12 bricks, a bouncing ball, and a three-cell paddle. Small enough that a 32-neuron hidden layer can learn it. Large enough that a table cannot. The observation includes two ball velocity components because a single frame is ambiguous—the same pixel layout can occur with the ball moving up or down, and the correct action differs. Without velocity, the same frame could mean the ball is going up or down, and the network has no way to tell which
Q-learning stores one value per state-action pair in a lookup table. On the cliff world example in part 1, that table had 48 states and 4 actions: 192 entries. It worked because every state had a short label and the agent visited each one many times. Breakout's 8x10 pixel grid changes this. The state is 80 pixel values plus 2 ball velocity components—82 inputs. Each pixel pattern is effectively unique. The agent will almost never see the exact same frame twice, and a table that has never seen this particular arrangement of ball, paddle, and bricks has nothing to say about it.
The solution taken by the Deep Q-Network (DQN) is function approximation. A neural network takes 82 numbers as input and outputs three Q-values, one for each possible action (left, stay, right). The network has a hidden layer of 32 neurons, to let it interpolate and pattern match: two frames with the ball one pixel apart share most of their weights and produce similar Q-values. The hidden neurons learn to detect these patterns, like ball near the paddle, or bricks clustered on one side, that no one programmed. The table memorizes whereas the network generalizes.
Three ideas make it trainable. Experience replay stores transitions in a buffer and trains on random samples, breaking the correlation between consecutive frames. A target network holds the TD target still long enough for the online network to converge—without it, every gradient step moves the bullseye. Epsilon decay shifts from pure random exploration (filling the buffer with diverse experience) to exploitation (using the learned Q-values) over 200 episodes.
The agent learns to play Breakout from raw pixels. In the greedy evaluation used in the lesson, it destroys 11 of 12 bricks and earns +9.18 reward. The Q-values at the start position tell us what the network expects: Right (0.817), Stay (0.776), Left (0.636). The ball starts moving down-right, and the network has learned that tracking its trajectory is better than moving away from it. The gap between Left and the other two is larger than the gap between Stay and Right—moving left is actively wrong, staying is merely passive. The network learned the asymmetry of the opening from 82 numbers and thousands of gradient steps.
DQN picks actions by argmax over a finite set. Left, stay, or right. That works when the actions are discrete. But it won’t work for ‘apply 0.73 units of force’ or ‘turn 12 degrees’, as there is no finite set to take the max over.
Schulman et al., 2017—Proximal Policy Optimization Algorithms
The Environment: Balance. The same inverted pendulum from Lesson 02, now with continuous state and continuous action. The choice was deliberate: it lets you compare 1983's binary push-left/push-right with 2017's smooth proportional torque on the same physics problem. Same goal, same pole, different algorithms.
Every lesson so far follows the same pattern: learn a value, use the value to pick actions. Bellman computed V(s). Q-learning estimated Q(s, a). DQN approximated Q(s, a) with a neural network. In every case, the agent asked "how good is this state or action?" and picked the action with the highest value.
Proximal Policy Optimization (PPO) does not learn values and derive a policy from them. Instead it learns the policy directly. The neural network is the policy—it takes the current state and outputs a probability distribution over possible actions. The agent samples from that distribution. Training adjusts it so that good actions become more probable and bad actions become less probable.
DQN: network(state) -> [Q(left), Q(stay), Q(right)] -> pick highest
PPO: network(state) -> (mean=0.3, std=0.6) -> sample 0.47DQN's network outputs three numbers and the agent picks the biggest. PPO's network outputs a bell curve and the agent draws a random number from it. You cannot take argmax over an infinite range, but you can sample from a bell curve centered anywhere. This is what makes continuous actions possible.
Three ideas make PPO stable. The clipped surrogate limits how far the policy can shift in one update—the ‘proximal’ in the name. If a good action would push the probability ratio past 1.2 (with epsilon=0.2), the gradient is zeroed. No single update can move the policy too far. Generalized Advantage Estimation blends TD and Monte Carlo credit assignment—the same bias-variance tradeoff from Lesson 3’s TD learning, now applied to advantages instead of values. Multiple epochs extract more learning from each batch of experience by running several gradient passes over the same data. This is safe because the clip prevents the policy from drifting too far from the collection policy.
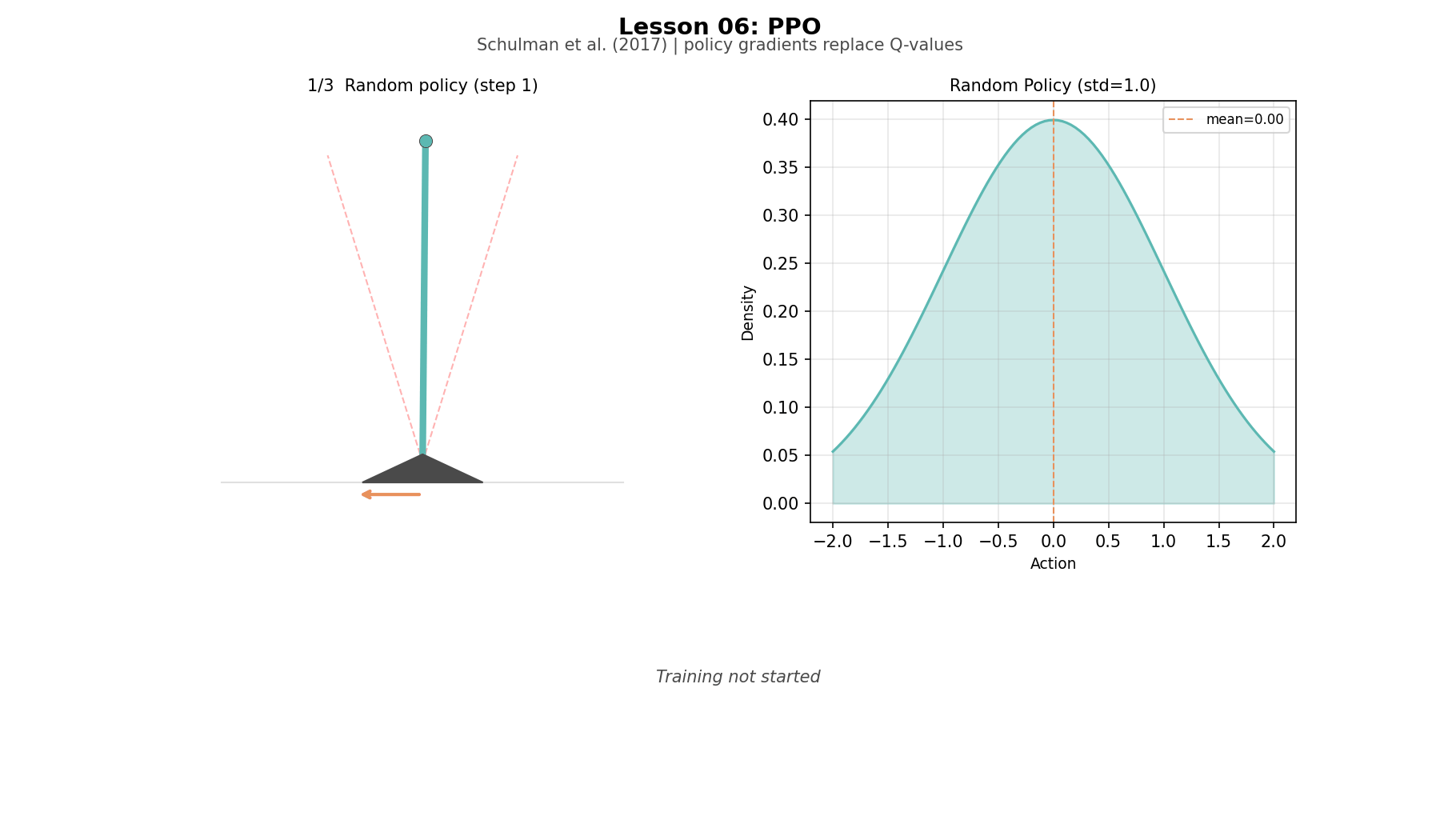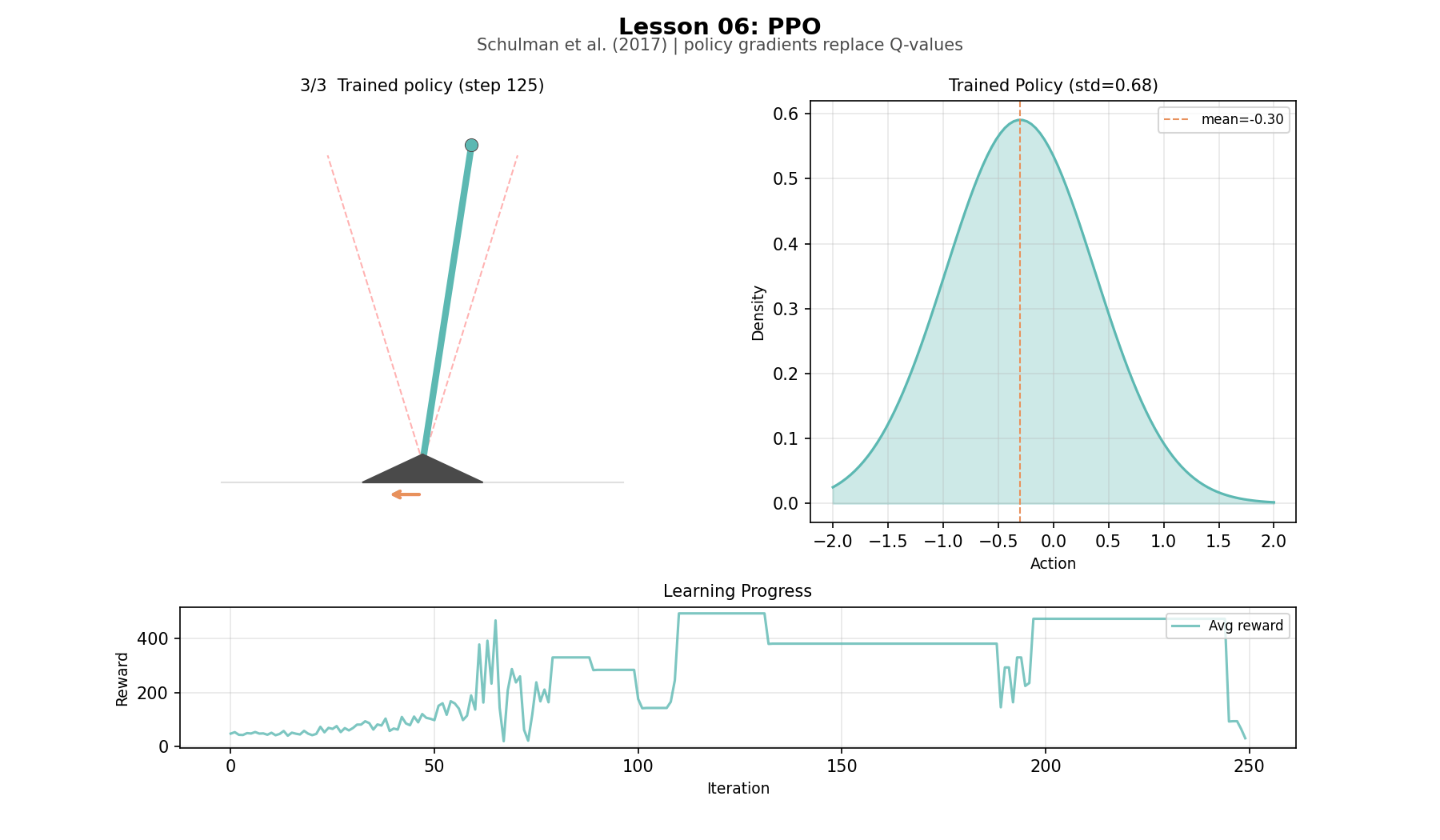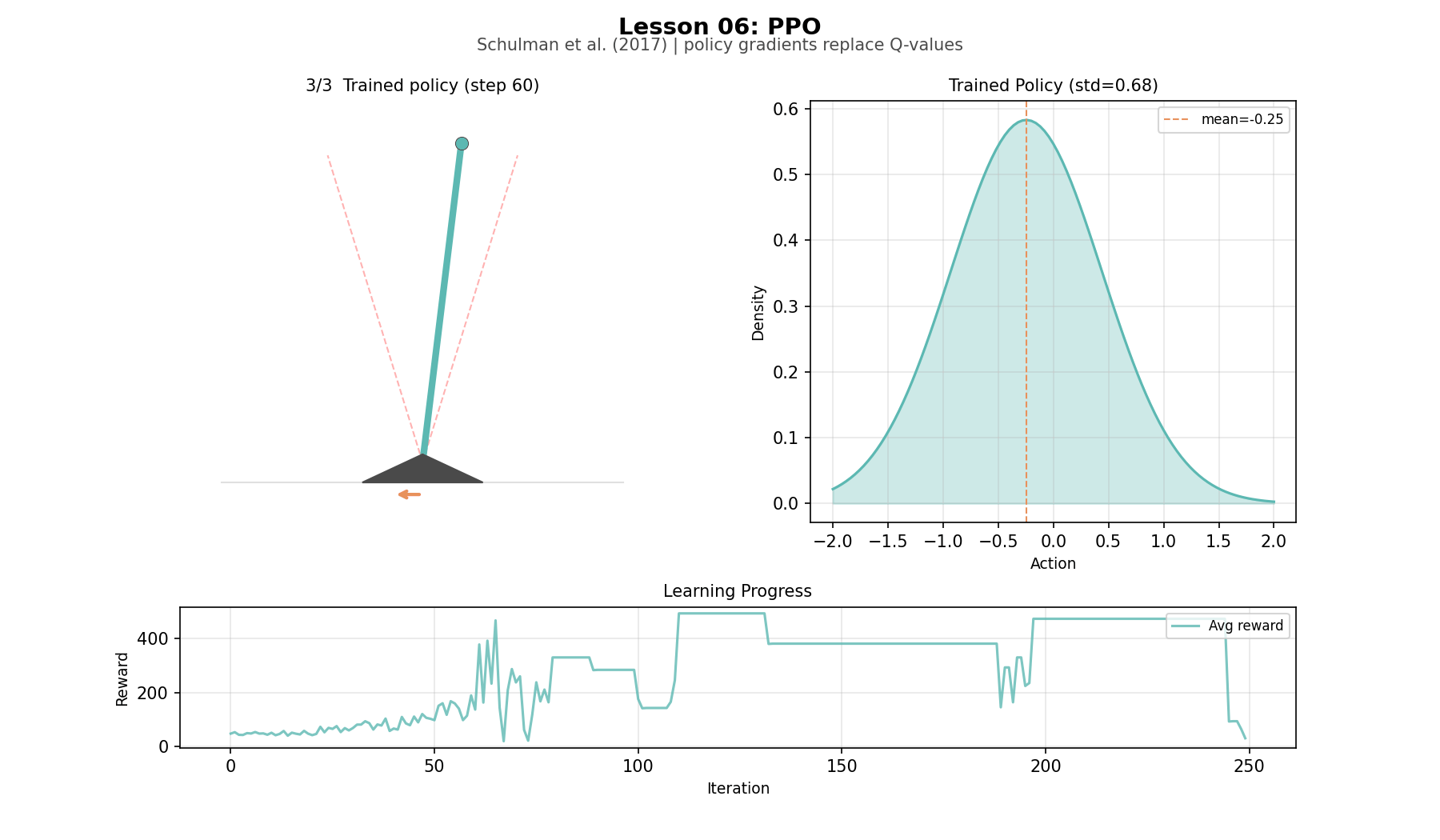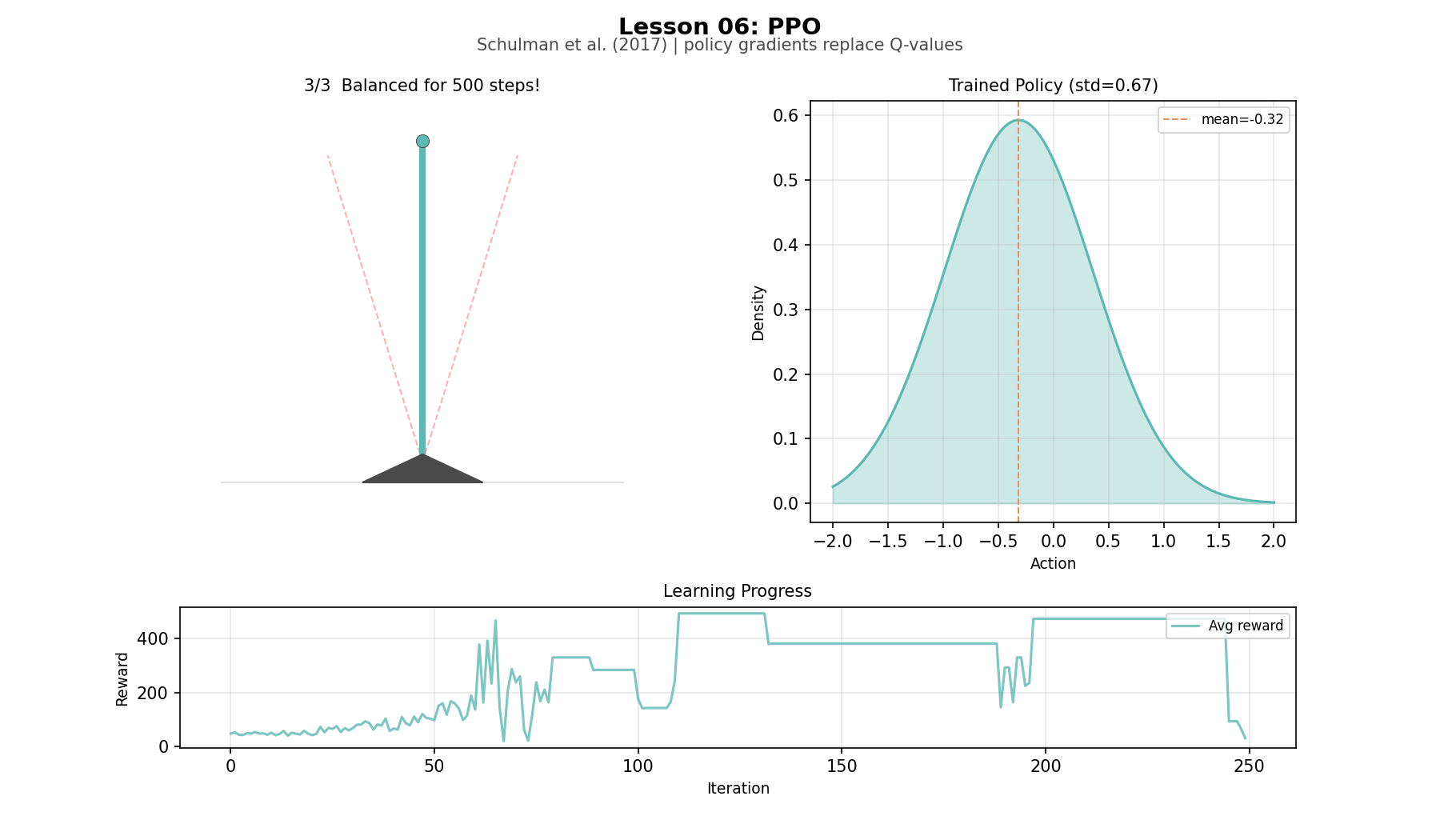
In our lesson, the agent survives 500 steps—the maximum. It keeps the pole within 0.16 radians of vertical, applying smooth proportional corrections: a small tilt gets a small push, a large tilt gets a strong one. Compare this to Sutton and Barto’s binary push-left/push-right. The standard deviation of the policy narrows from 1.06 to 0.53 over training—the agent is committing to its strategy, exploring less, exploiting more.
But PPO learns from real experience only. Every training step requires actually running the environment. If the environment is expensive—a robot, a full simulator, the real world, this is wasteful and difficult to scale.
Hafner et al., 2023—Mastering Diverse Domains through World Models
The Environment: Pixel Point Mass. A 16x16 pixel grid with agent trying to find a target. It’s a very minimal world-model task: the physics is a ‘point-mass’, which means position, velocity, force are all there. The agent applies a 2D force to move toward the target. It sees 256 pixel values, not coordinates, and must learn to navigate from pixels alone. It’s simple enough that the world model can learn the pixel structure and complex enough that the policy does not converge—which is part of the point of this lesson.
Dreamer asks: what if the agent could practice in its head? Instead of learning a value function or a policy from real transitions, Dreamer learns a model of the world itself—what happens next given a state and an action—then imagines thousands of trajectories without touching the real environment. Real data trains the world model. Imagined data trains the policy.
This matters because real environment steps are expensive. Physics must be simulated, pixels must be rendered, the agent must wait for the result. In robotics, each step means a physical robot moving and risking damage. A world model turns one real episode into many training episodes. This is sample efficiency—getting more learning out of fewer real interactions.
The world model has four parts. An encoder compresses 256 pixels into 32 numbers—the latent state, a hidden summary that captures what matters (agent and target positions) and discards what does not (240+ black pixels). A Gated Recurrent Unit (GRU) predicts how the latent state changes when the agent acts—a learned physics engine. Unlike the feed-forward networks from L05, the GRU is recurrent: it carries hidden state from step to step, remembering history through learned gates that control what information to keep and what to discard. A decoder reconstructs pixels from the latent state (forcing the encoder to preserve useful information). A reward head predicts reward (forcing the dynamics to track reward-relevant features).
During training, the world model sees real observations at every step—teacher forcing. During imagination, it runs open-loop: the GRU predicts forward with no real observations to correct it. Early imagination steps track reality. Later steps drift as prediction errors compound. This is the fundamental tradeoff: imagination is free but imperfect. Once trained, the agent imagines entire trajectories without touching the real environment. The encoder compresses a real frame into 32 numbers. The actor chooses an action. The GRU predicts the next latent state. The reward head scores it. Repeat. No pixels rendered, no physics simulated—the entire step happens in 32 numbers.
The actor and critic operate entirely in latent space, never seeing pixels. Lambda returns and advantages work the same as in L06—the only difference is that the rewards and values come from the world model's predictions rather than from the real environment. The world model learns to reconstruct pixel frames well enough for the decoder to recreate the scene from its compressed representation. Reward improves during training, then regresses—the world model and the policy are learning simultaneously, and when one improves the other's data shifts underneath it.
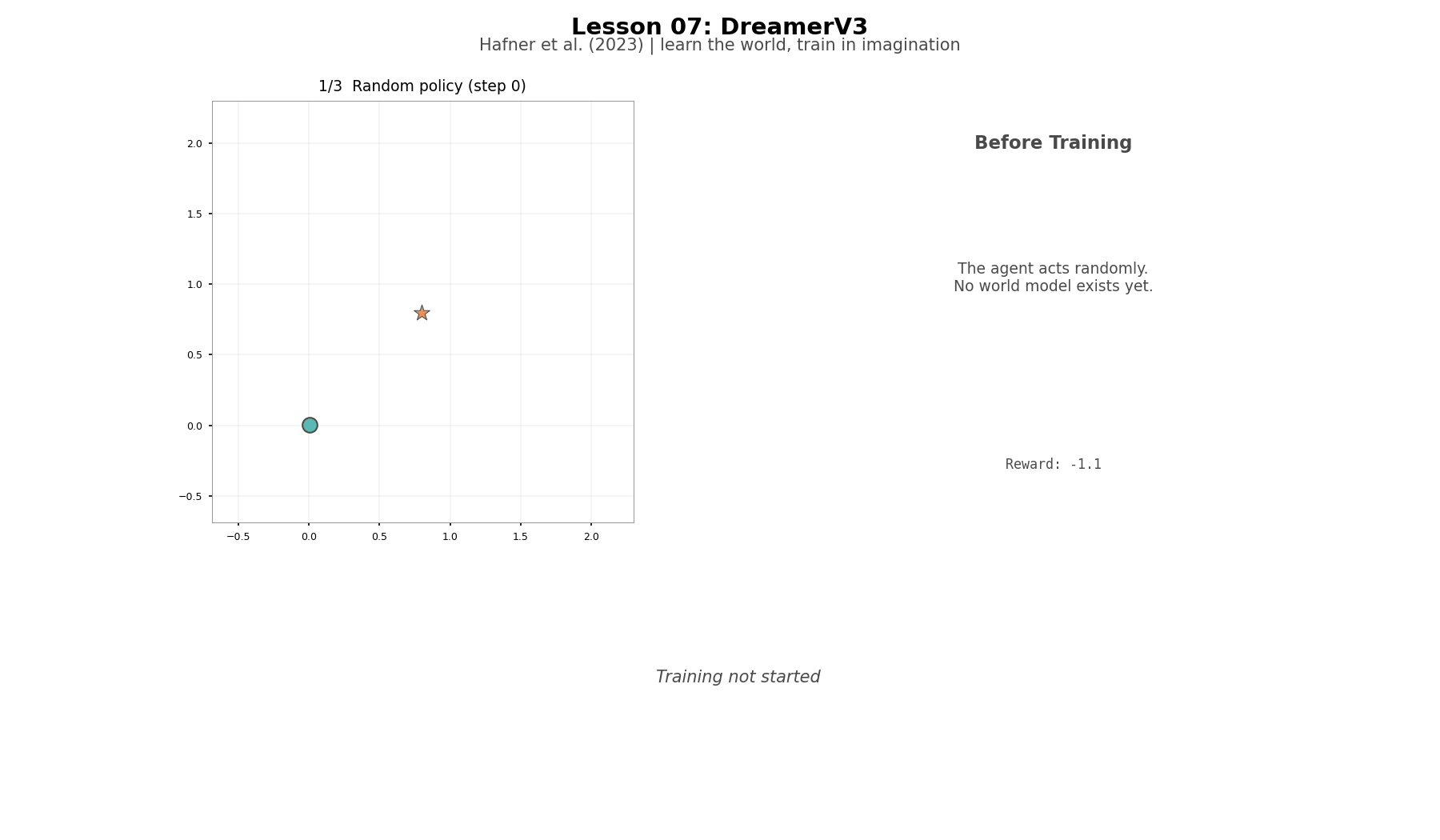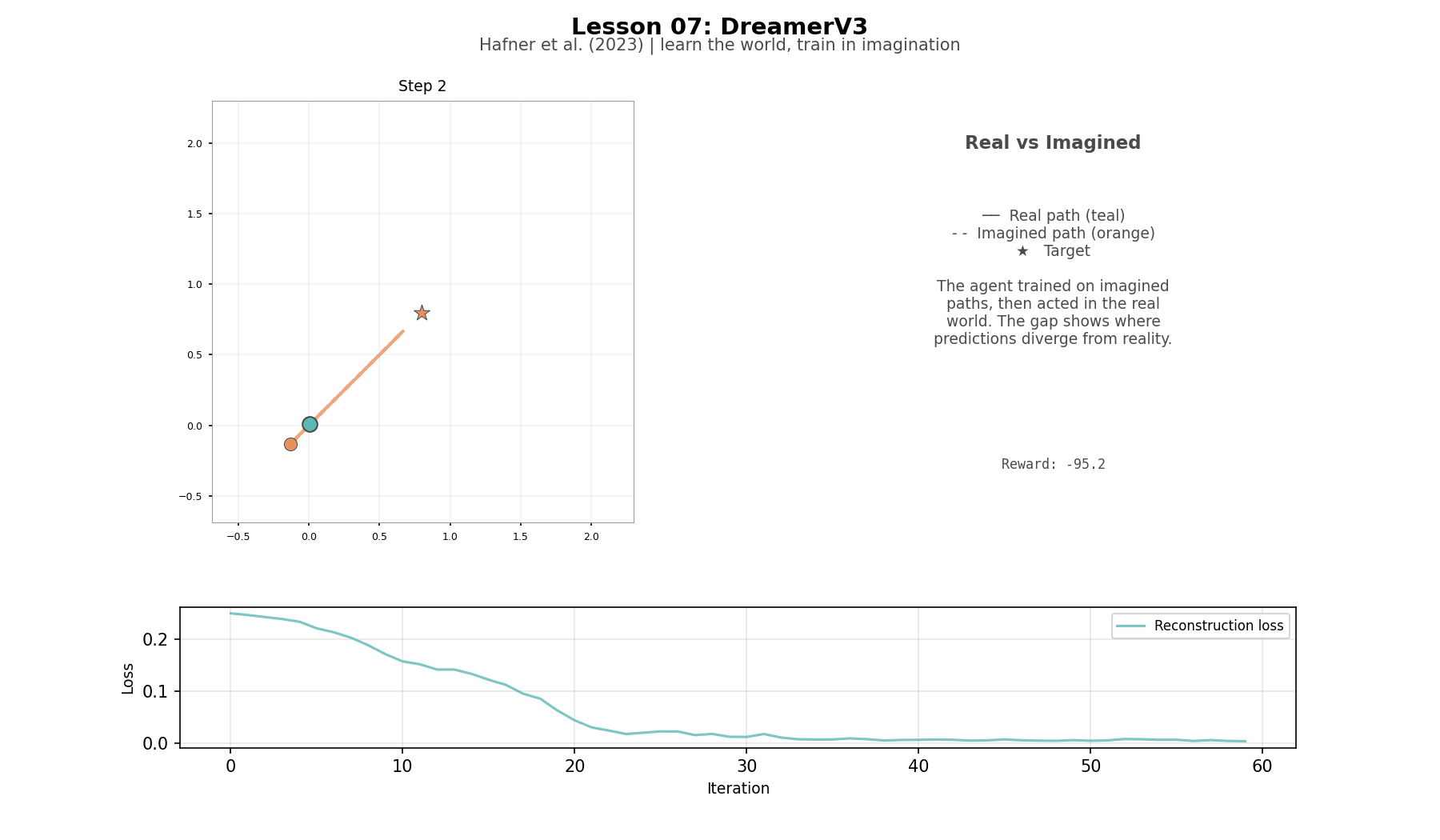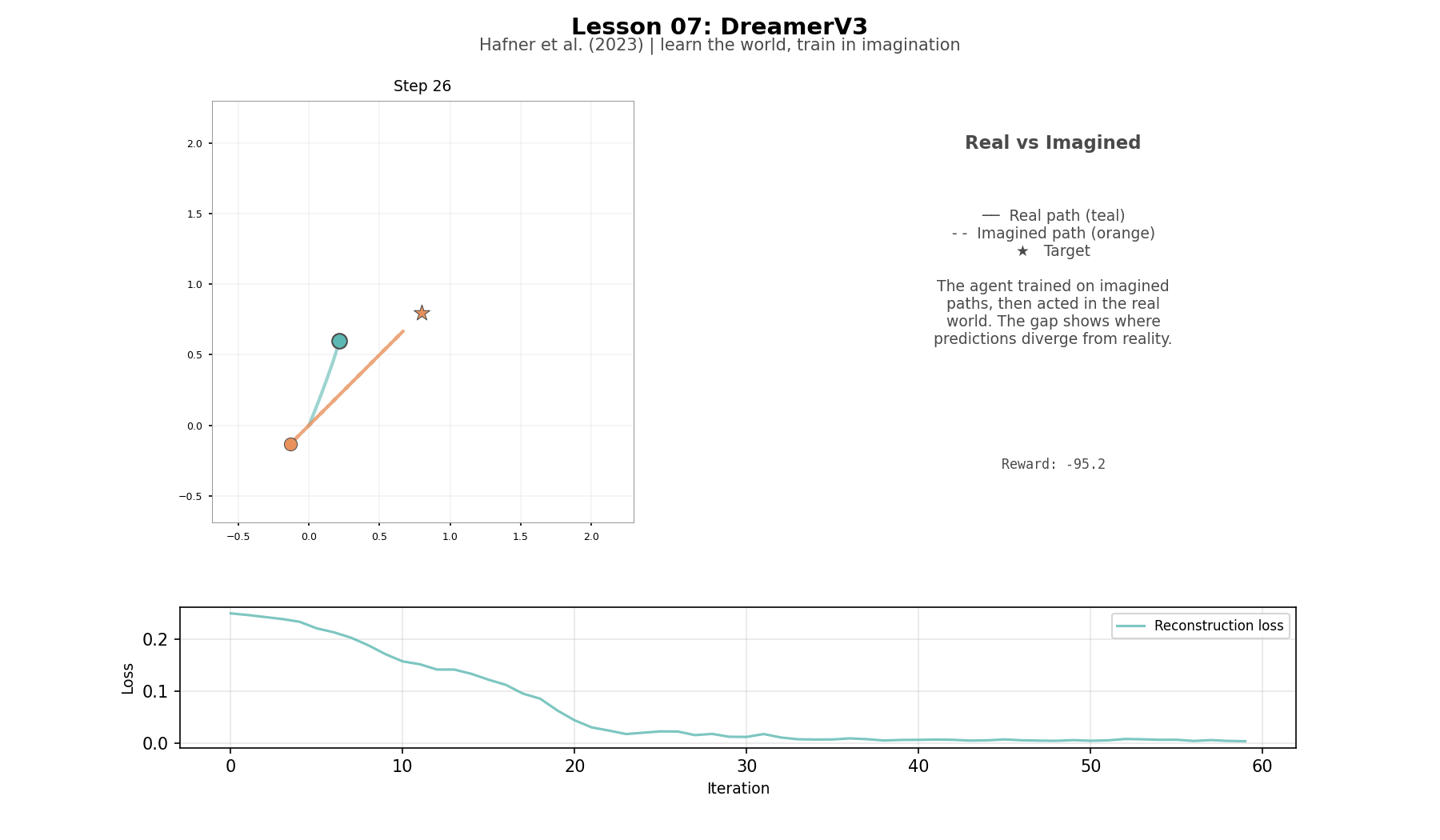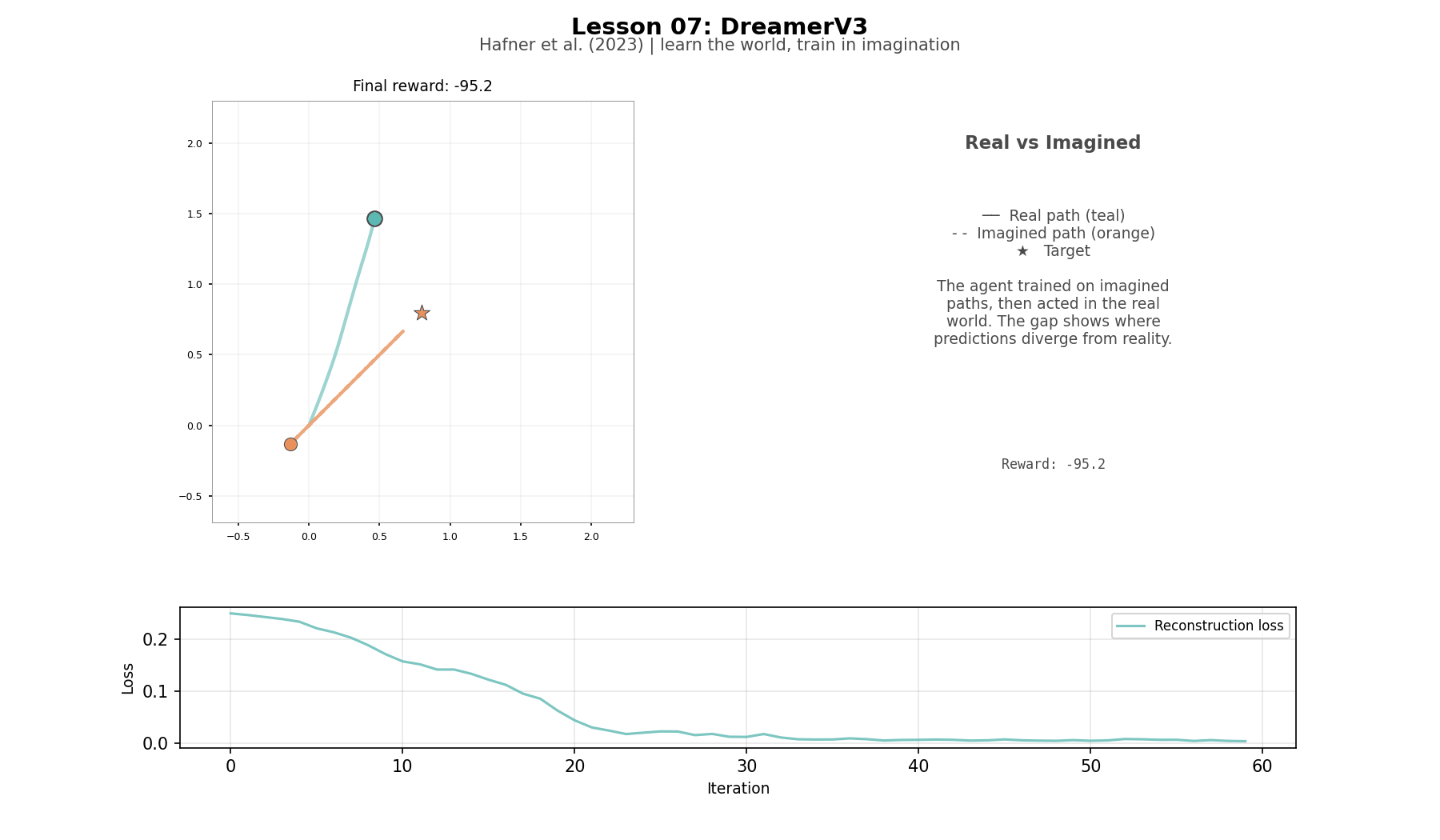
The agent does not reach the target. Training reward reached -30, but greedy evaluation is essentially random. Two things explain the gap. The training reward comes from rollouts where the agent explores—it samples actions from a bell curve, and sometimes gets lucky. The greedy eval always takes the mean action, with no noise to stumble into better positions. And the training reward was a snapshot—the world model and the policy are still changing underneath each other, and by the end of training the policy had drifted from its best point. On top of both, there is an input mismatch: during imagination, the actor trains on the GRU's predicted states, but during real collection and evaluation it sees the encoder's output from actual pixels. These are not the same numbers. The full DreamerV3 solves this with the RSSM, which blends the GRU's prediction with the real observation at every step so the actor always sees a consistent input.
Three further simplifications compound the problem: teacher forcing without open-loop practice means imagined trajectories drift; a deterministic GRU without uncertainty estimation means the model cannot know when its predictions are unreliable; and a minimal training budget means the actor-critic does not have enough imagined experience to converge. Each is a named simplification, each is something the full paper addresses, and the partial success is more instructive than a clean solve.
What Building Made Visible
The network interpolates, it does not memorize
The Q-value spread at Breakout's start position—Right: 0.817, Stay: 0.776, Left: 0.636—reveals what the network learned about the opening. The ball starts moving down-right. The network prefers Right because the paddle needs to track the ball's trajectory. The gap between Left and the other two is larger than the gap between Stay and Right: moving left is actively wrong, staying is merely passive. The network learned the asymmetry of the opening from raw pixels, not from any programmed knowledge of ball physics. That is function approximation: not understanding, but interpolation that works.
A bell curve is a very different kind of knowledge to a Q-value
DQN's output is three numbers. PPO's output is a shape, a Gaussian that narrows as the agent learns. Watching the standard deviation drop from 1.06 to 0.53 over training tells a story that reward curves cannot: the agent’s policy distibution is narrowing around a strategy. The slight widening after iteration 150, followed by recovery, is the policy exploring refinements after reaching near-optimal performance. The clip prevents this exploration from becoming collapse. The bell curve does not just encode what action to take, it encodes how certain the agent is, and watching that certainty grow and occasionally retreat is one of the more revealing dynamics in the project.
Imagination is cheap but imperfect
The world model learns pixel structure—the reconstruction error drops steadily—but the greedy evaluation is essentially random. Two things explain the gap. First, the training reward comes from rollouts where the agent explores: it samples actions from a bell curve, and sometimes gets lucky. The greedy eval always takes the mean action, with no noise to stumble into better positions. Second, the training reward was a snapshot. The world model and the policy are still changing underneath each other, and by the end of training the policy had drifted from its best point. On top of both, there is an input mismatch. During imagination, the actor trains on the GRU's predicted states. During real collection and evaluation, the actor sees the encoder's output from actual pixels. These are not the same numbers, so the actor is being tested on inputs it mostly did not train on. The full DreamerV3 solves this with the RSSM, which blends the GRU's prediction with the real observation at every step so the actor always sees a consistent input. The teaching implementation was designed to surface these gaps. A simplified Dreamer that cleanly solved the task would demonstrate less about what makes the real thing hard..
Building with AI
The collaboration was the same as Part 1. Claude Code wrote the implementation, I directed the architecture and wrote the narratives. The pattern scaled. Neural network backpropagation, GRU dynamics, the clipped surrogate objective—these are precise enough that correctness is verifiable and hard to fake. The world model was the hardest: six networks training simultaneously, two learning phases, gradients flowing through a recurrent model. The constraint—no frameworks, no autograd—meant every gradient had to be derived and implemented by hand. Where we spent the most time was refining the lesson text and the visualizations.
The code is slow. The environments are small. DreamerV3's six networks train in pure Python lists, which is exactly as fast as that sounds. None of that matters. What matters is that when the DQN agent tracks a ball across pixels, you can open the forward pass and see 82 numbers become 3 Q-values through 32 neurons. When PPO narrows its bell curve, you can trace the clipped surrogate back to a ratio of two Gaussian densities. When Dreamer imagines a trajectory that diverges from reality, you can watch the GRU accumulate error step by step.
The Full Arc
The seven lessons span 66 years. Bellman computed optimal values from a known model. Barto and Sutton learned from interaction. Sutton bootstrapped from predictions. Watkins turned prediction into control. Mnih et al replaced the table with a network. Schulman et al replaced the argmax with a distribution. Hafner et al replaced the environment with a dream. Each step solved a problem the previous one could not and each step introduced a new challenge. The world model that closes the series is also the one that does not fully work—and that is a fair summary of where the field stands today. Many of the core ideas are settled, but the engineering is not. The series started with the question every RL agent asks: given what I know, what should I do next? Seven papers, seven answers, same question. From Bellman to Hafner, the machinery changed dramatically but the question did not.