Policywerk: Building Reinforcement Learning from First Principles
Most reinforcement learning code starts after the interesting part. You import an environment, import an agent, call step(), and watch returns go up. Learning happened, but the mechanism stays behind glass, the same way you cannot see combustion by looking at a car.
That hides one of the most interesting things about reinforcement learning: the system does not receive labeled correct actions, it only receives reward, and is not given the answer. Supervised learning gives you labels. Unsupervised learning gives you structure. RL gives you a reward after each action and leaves the rest to you. That is what makes it compelling. You can tell an agent improved. You often cannot tell how.
Policywerk does for reinforcement learning what modelwerk did for neural networks: it builds the whole thing from scalar arithmetic, in plain Python, with no frameworks. The constraint is the same: standard library only, no numpy, no torch, matplotlib allowed for visualization. The point is the same too. When an agent learns to converge on the cliff edge instead of selecting a less risky path, you can trace the update that caused it: three nested loops, nowhere to hide. The aim is to have seven lessons in total, and in this post we’ll cover the first four.
Four lessons, four missing pieces
The first four lessons follow a simple pattern: each paper solves a problem the previous one could not. From 1957 to 1989, the core ideas of modern RL come into view one mechanism at a time.
Bellman, 1957. A Markovian Decision Process.
Start with the simplest case: a complete model of the world. Every transition probability and every reward is known in advance. Value iteration computes the optimal policy by working backward from the goal, sweep by sweep, until the values stop changing. On a small gridworld, reward information moves through the map like a wave. The algorithm is almost mundane: a few scalar multiplies, adds, and a max() in a loop. But the limitation is obvious. You only get to do this when the world is fully specified.
Barto, Sutton & Anderson, 1983. Neuronlike Adaptive Elements That Can Solve Difficult Learning Control Problems.
Now remove the world model. The agent has to act, observe what happens, and learn from the result. Two simple adaptive elements split the job: the critic estimates how things are going, the actor produces the next action. Together they learn to balance an inverted pendulum. The historical surprise is how durable the structure has been. Actor and critic are still with us, 40 years later, in PPO, SAC, and a great deal else. Building the system from single-neuron components makes the architecture look smaller, not larger. The limitation is that the learning signal is noisy, the method is parameter-sensitive, and every improvement has to be bought through experience.
Sutton, 1988. Learning to Predict by the Methods of Temporal Differences.
Temporal-difference learning removes another bottleneck. Instead of waiting until the end of an episode, the agent updates its estimate after every step by bootstrapping from its current prediction of the next state. In a five-state random walk, you can watch the estimates move toward the truth before the final outcome is fully known. Information propagates backward through experience, the same wave as Bellman's value iteration, but now it does so from samples rather than from a known model. The limitation here is different: TD learning tells you how good states are under a policy. It does not yet tell you what action to take.
Watkins, 1989. Learning from Delayed Rewards.
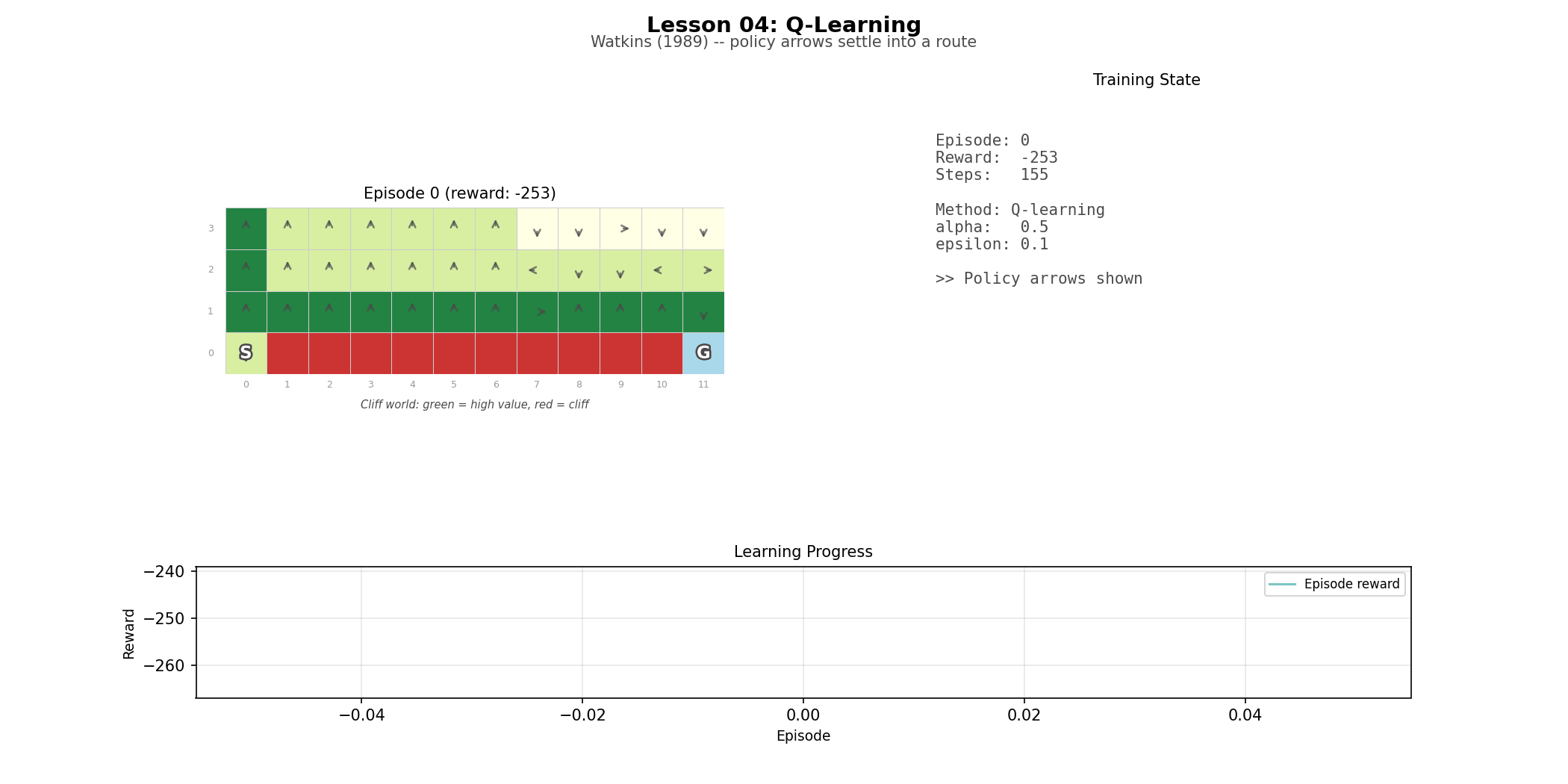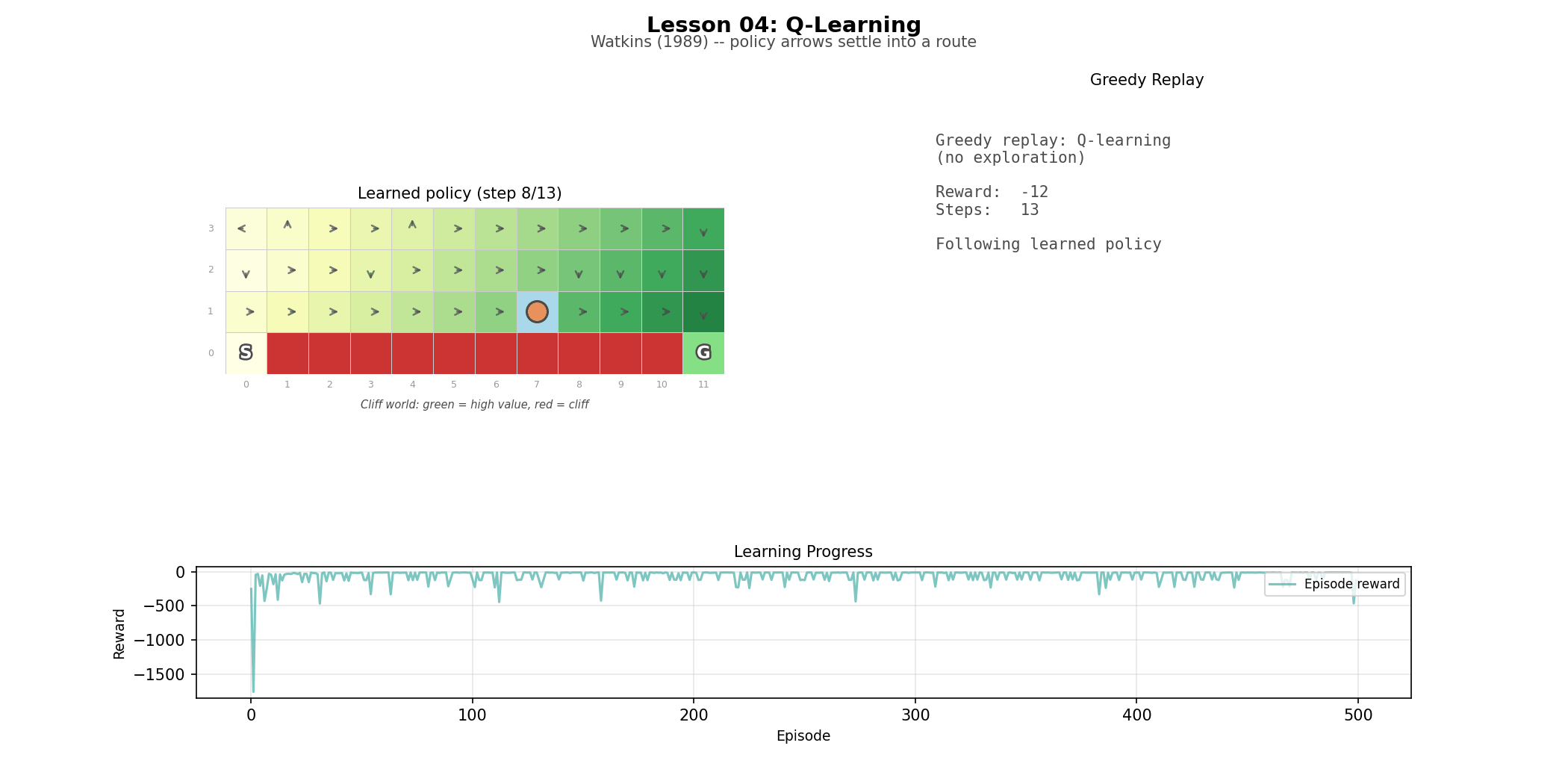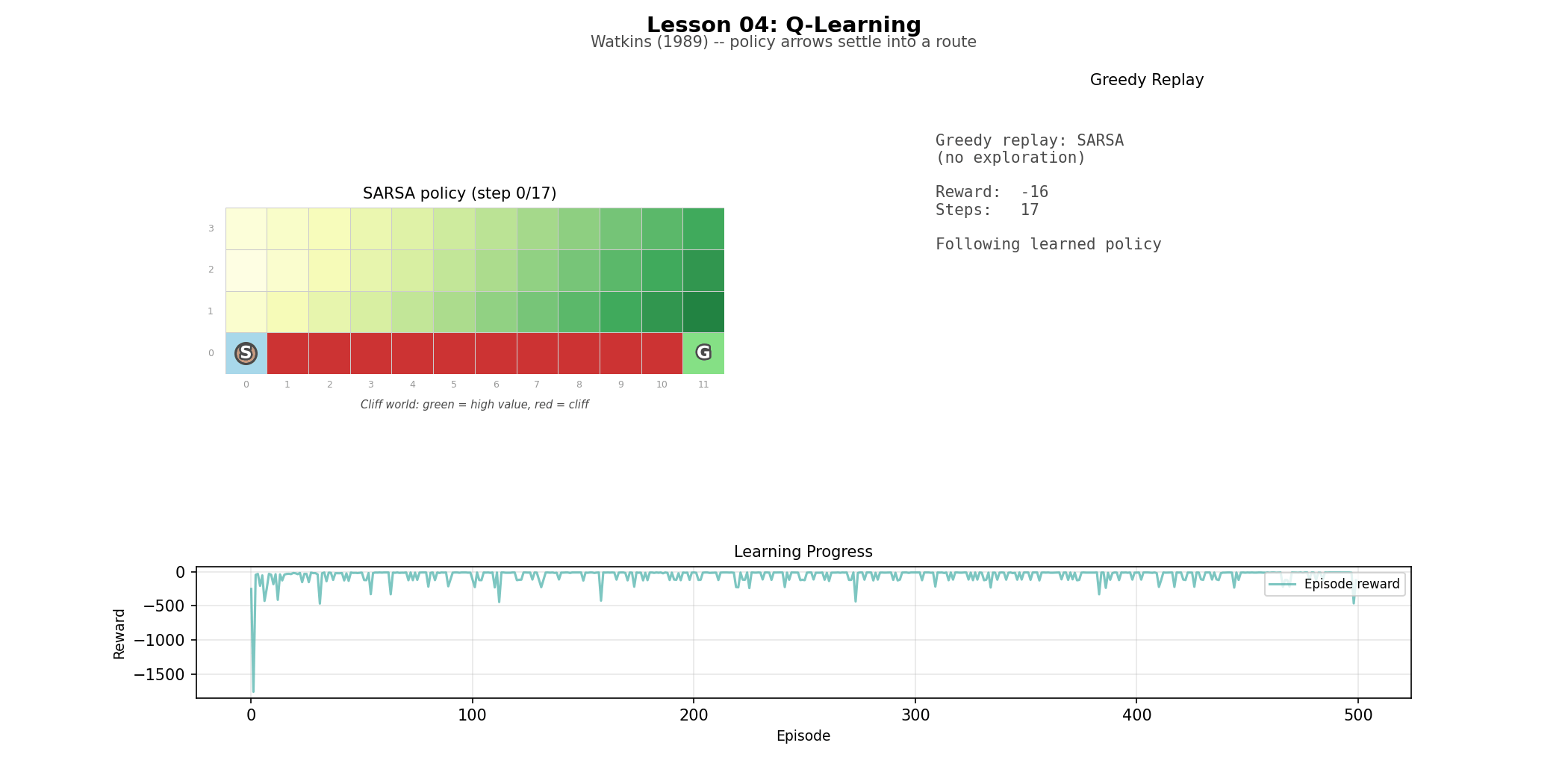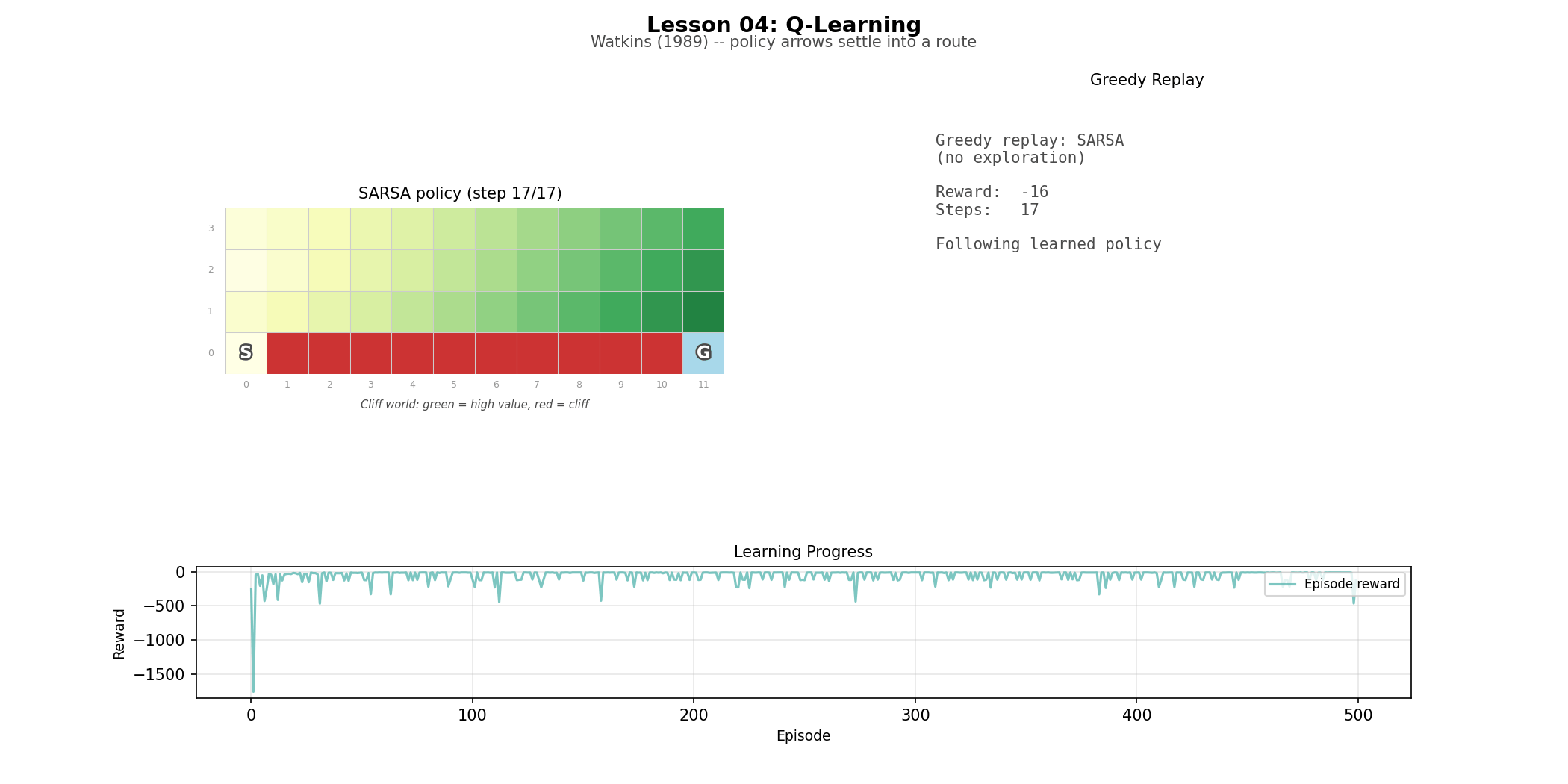
Q-learning turns prediction into control. Instead of learning V(s), the value of a state, it learns Q(s, a), the value of taking a particular action in that state. The key change is a single word in the update rule: max. Q-learning asks what the best possible continuation would be from the next state, regardless of what action was actually taken there. That is what makes it off-policy. It also makes the cliff world an unusually revealing environment. The learned policy can be optimal, and still look bad during training when exploration keeps pushing the agent into danger.
The constraint
Same rule as modelwerk: Python standard library only. No numpy, no torch, no tensorflow. Matplotlib is the sole exception, used only for visualization. The constraint is not about purity. It is there to make the machinery visible. The point is to be able to trace a Q-value update from action selection all the way down to a scalar multiply and understand every step in between. Everything composes upward: scalar operations become vector-like structures, those become value functions and policies, those become agents interacting with tiny environments designed to make one idea visible at a time.
The environments
Each lesson has an environment that makes one concept visible:
Gridworld (L01): a 5×5 grid with a goal, a pit, and a wall. Small enough that every state can be inspected directly. The animation makes the point clear: values propagate backward through the map sweep by sweep.
Balance (L02): a simplified inverted pendulum with a small discrete state space. The agent goes from immediate failure to sustained control quickly enough that the actor-critic split stays visible.
Random walk (L03): five states in a chain, with known true values. About as small as a TD example can be while still showing the mechanism clearly.
Cliff world (L04): a 4×12 grid with a cliff along the bottom row. The environment that makes the difference between Q-learning and SARSA legible at a glance—you can watch one agent converge the edge and the other optimise for a longer but less risky option.
Each lesson in the code produces an animated artifact with a three-pane layout: environment state, algorithm internals, and training trace. Static plots tell you what was learned. Animation makes it easier to see how learning unfolds. You can see the lesson output as plain markdown, and as well as the lessons, the core reinforcement learning concepts are here.
What building made visible
What follows are four moments where the code became easier to see than the paper.
1. Value iteration is less abstract than it sounds
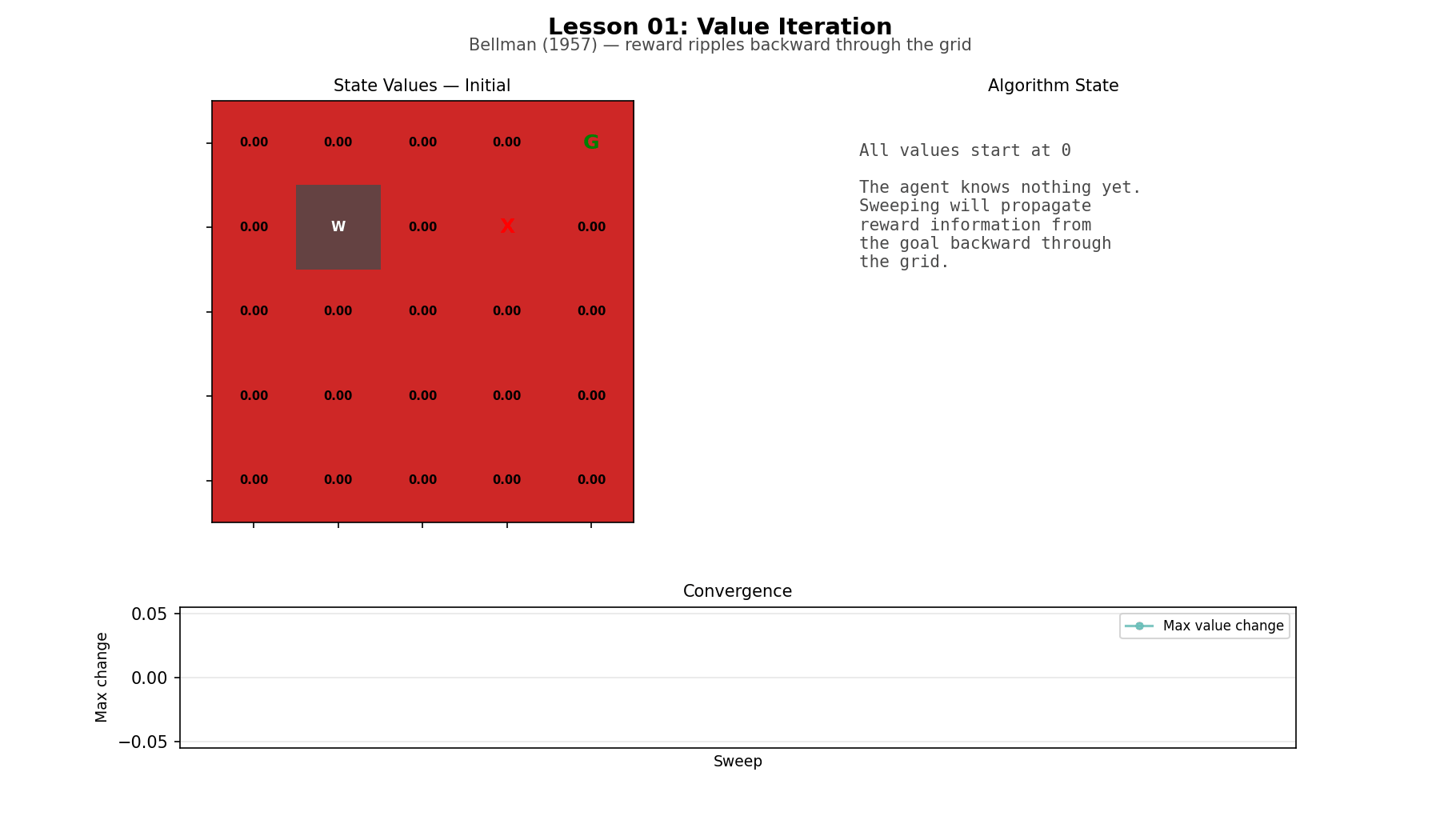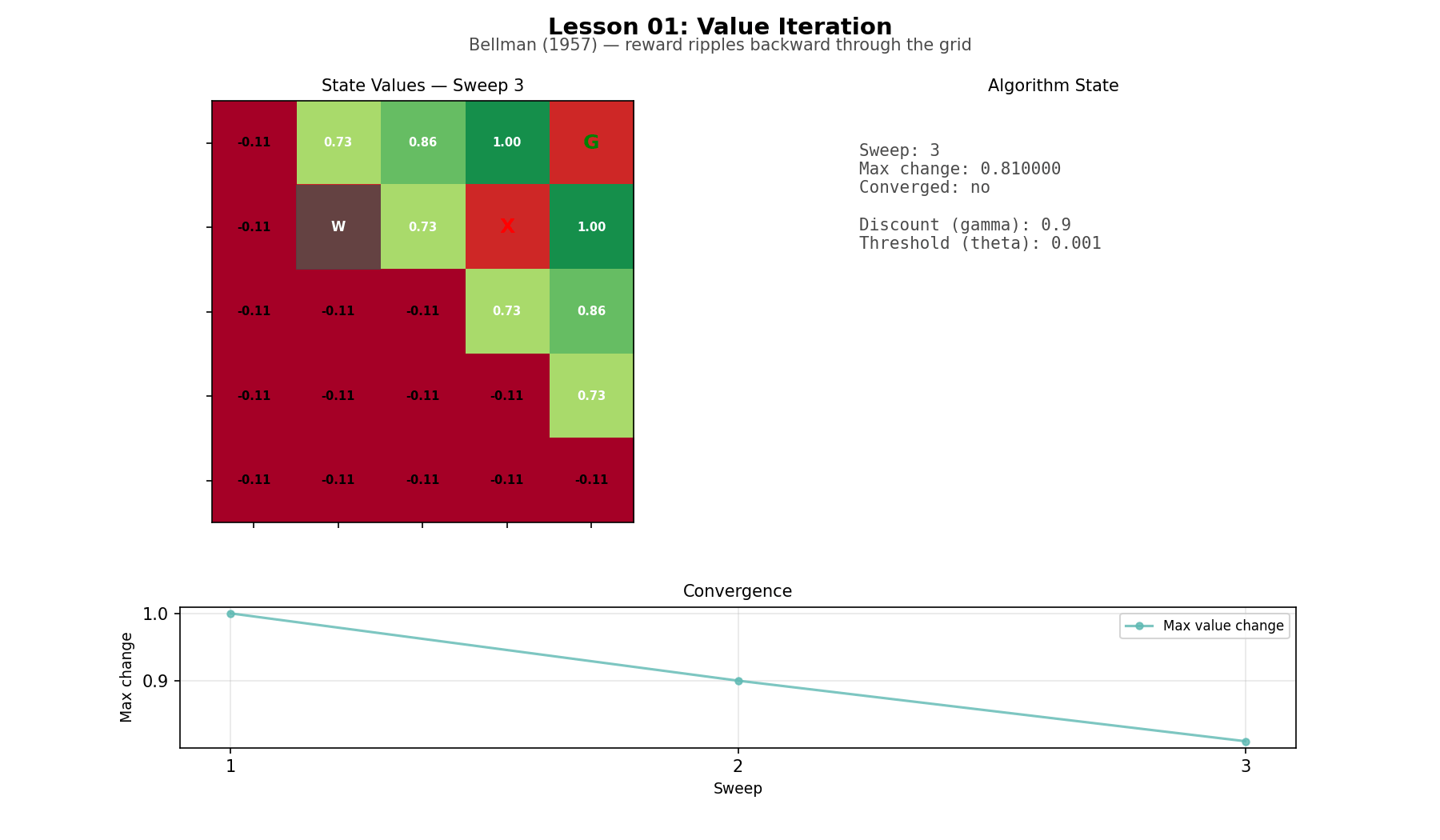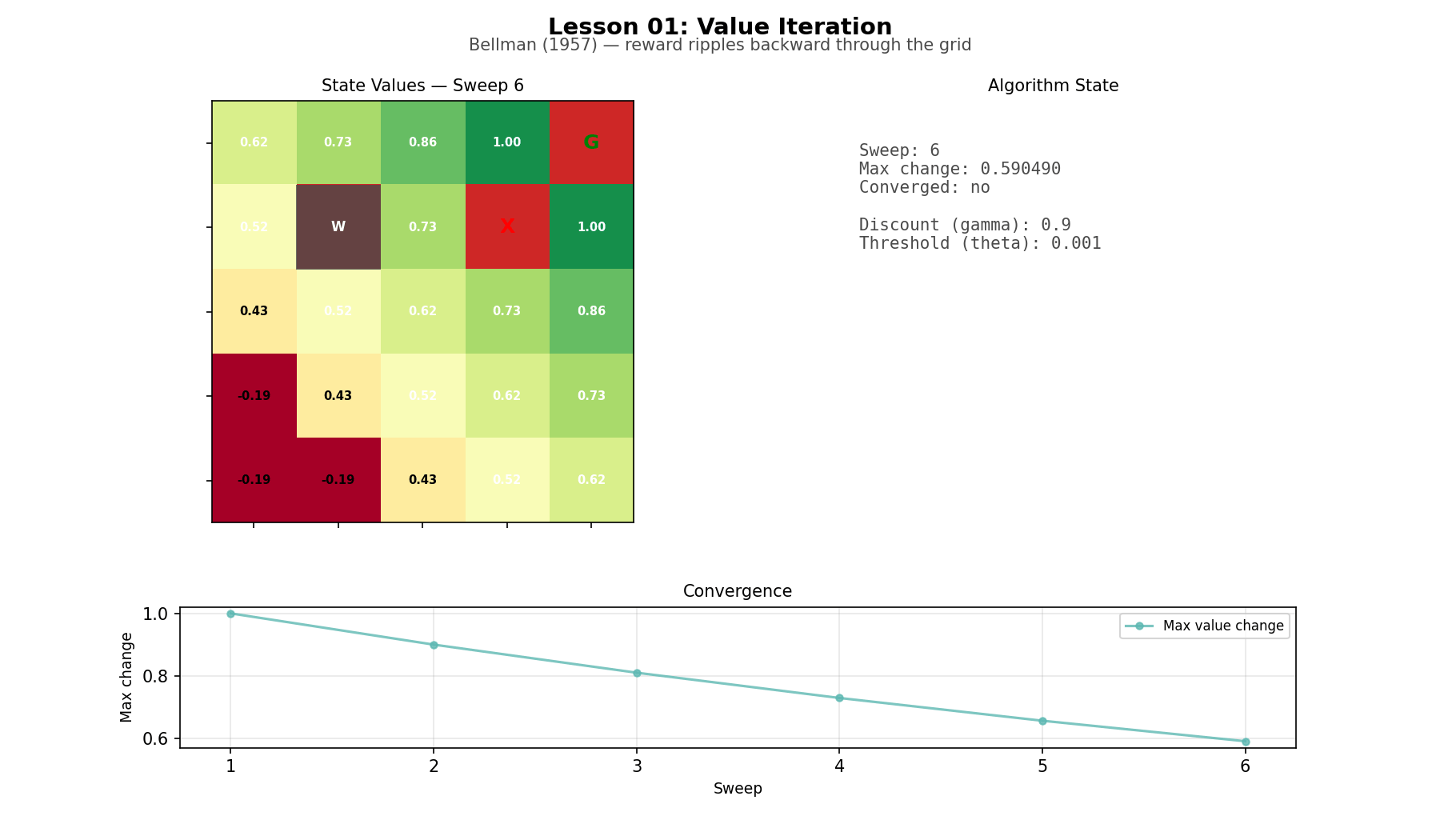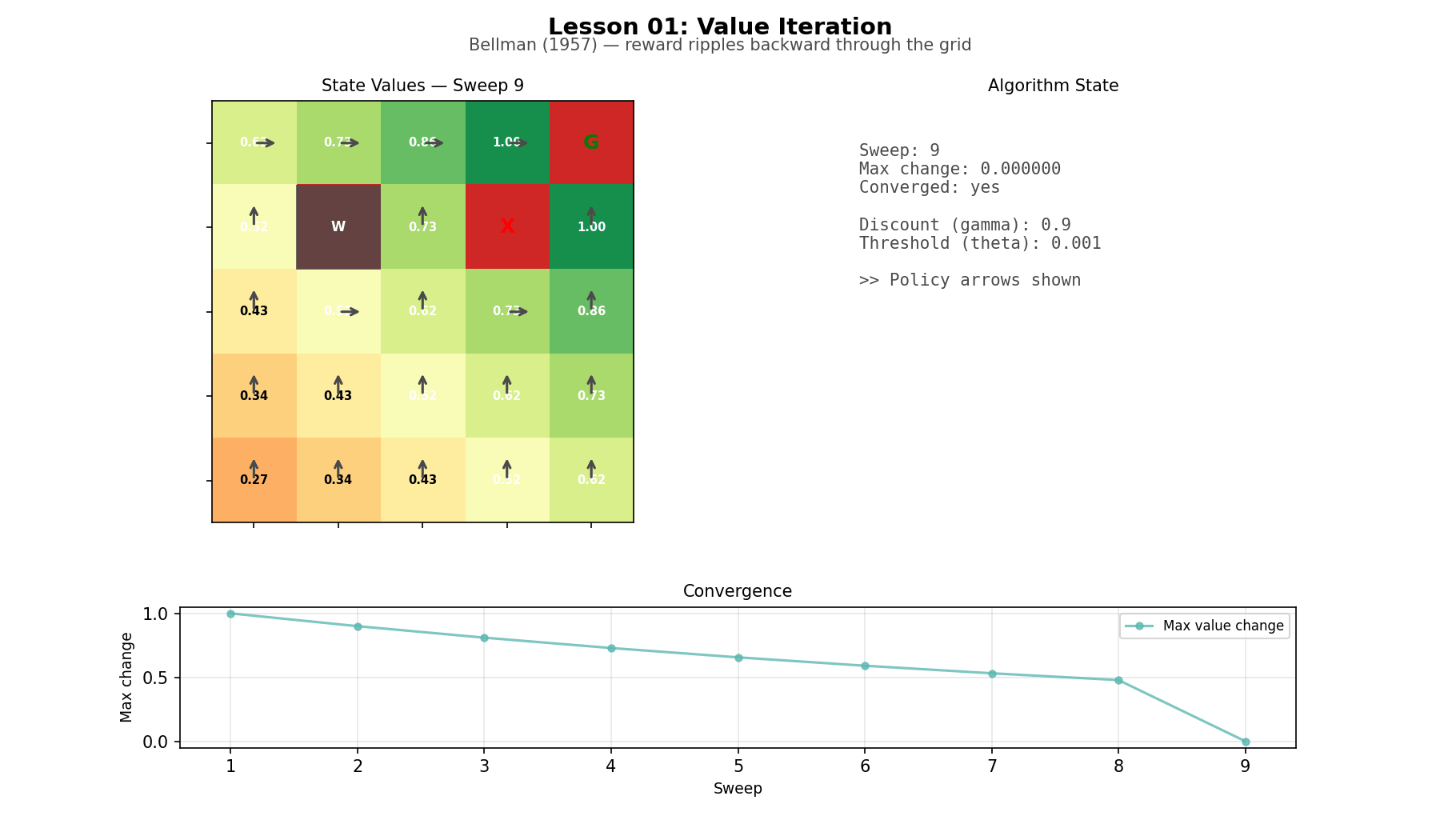
Value iteration on the gridworld
Bellman’s equation has a reputation for feeling mathematical. In code it feels straightforward. Run a sweep over the grid, update each cell from its neighbors, repeat. Reward information moves outward one step at a time until the values settle. The optimal policy falls out almost as a side effect: from each cell, move toward the neighbor with the highest value. The whole method is smaller than the environment it runs on.
2. The actor-critic split was already there in 1983
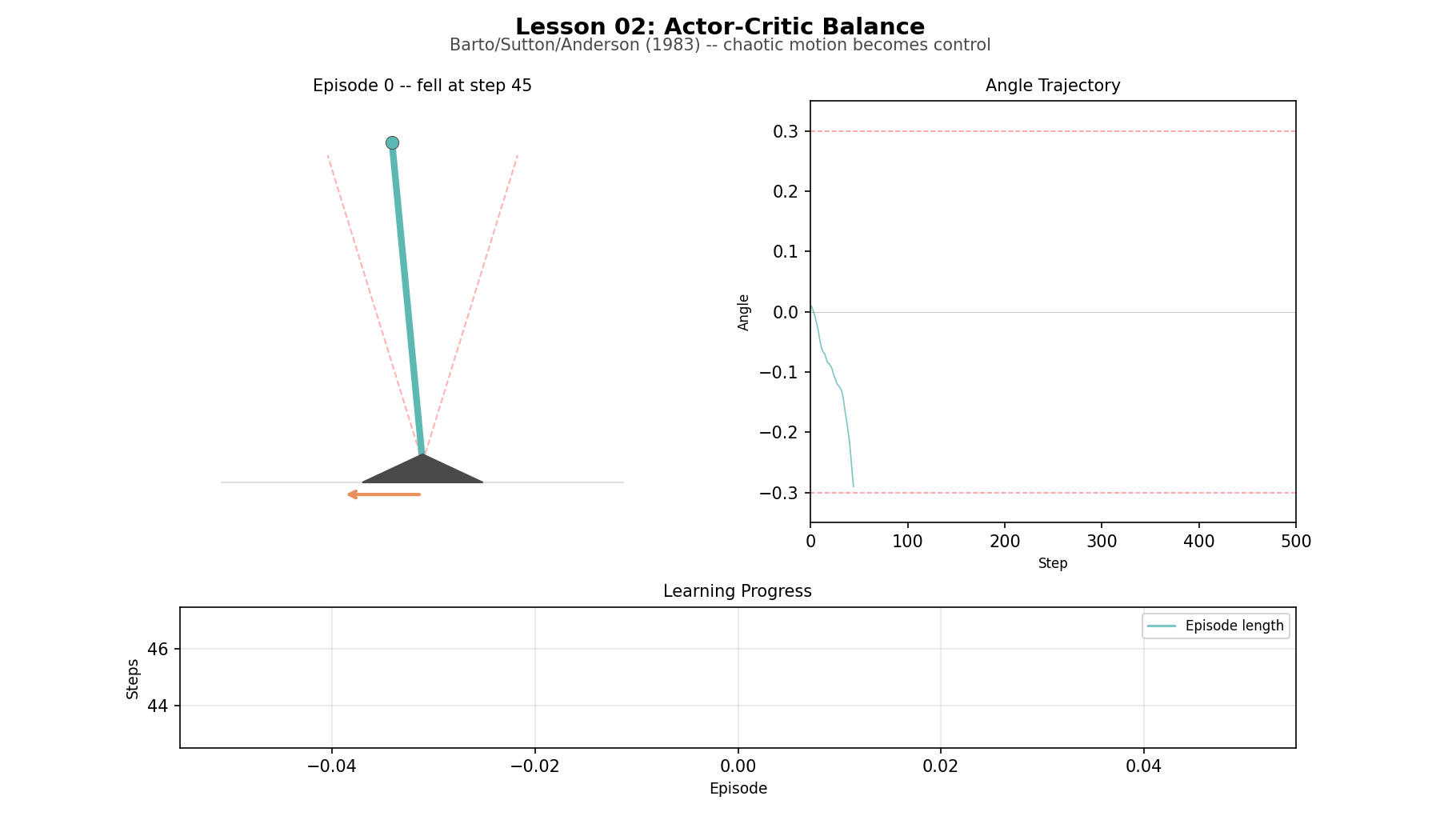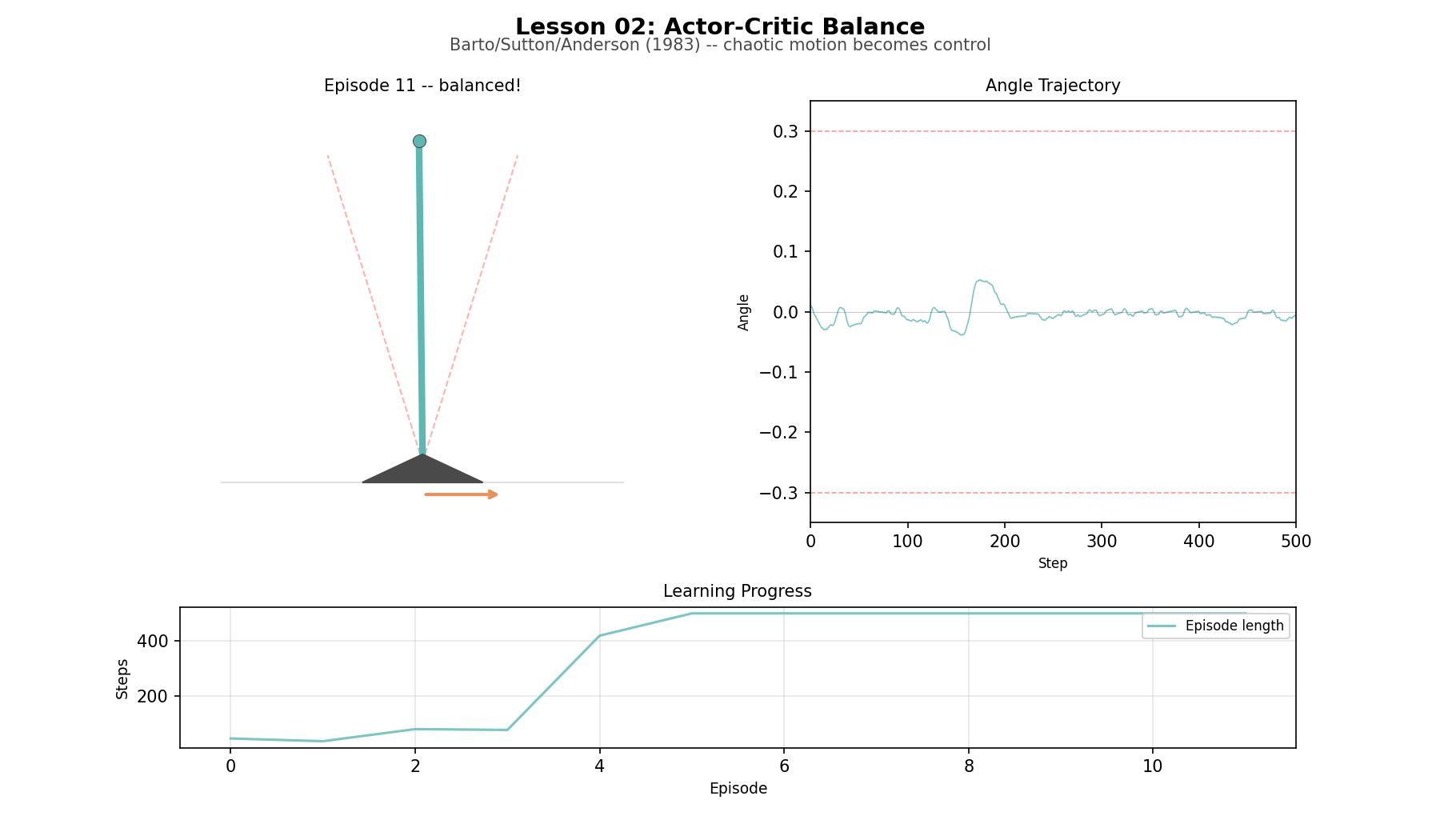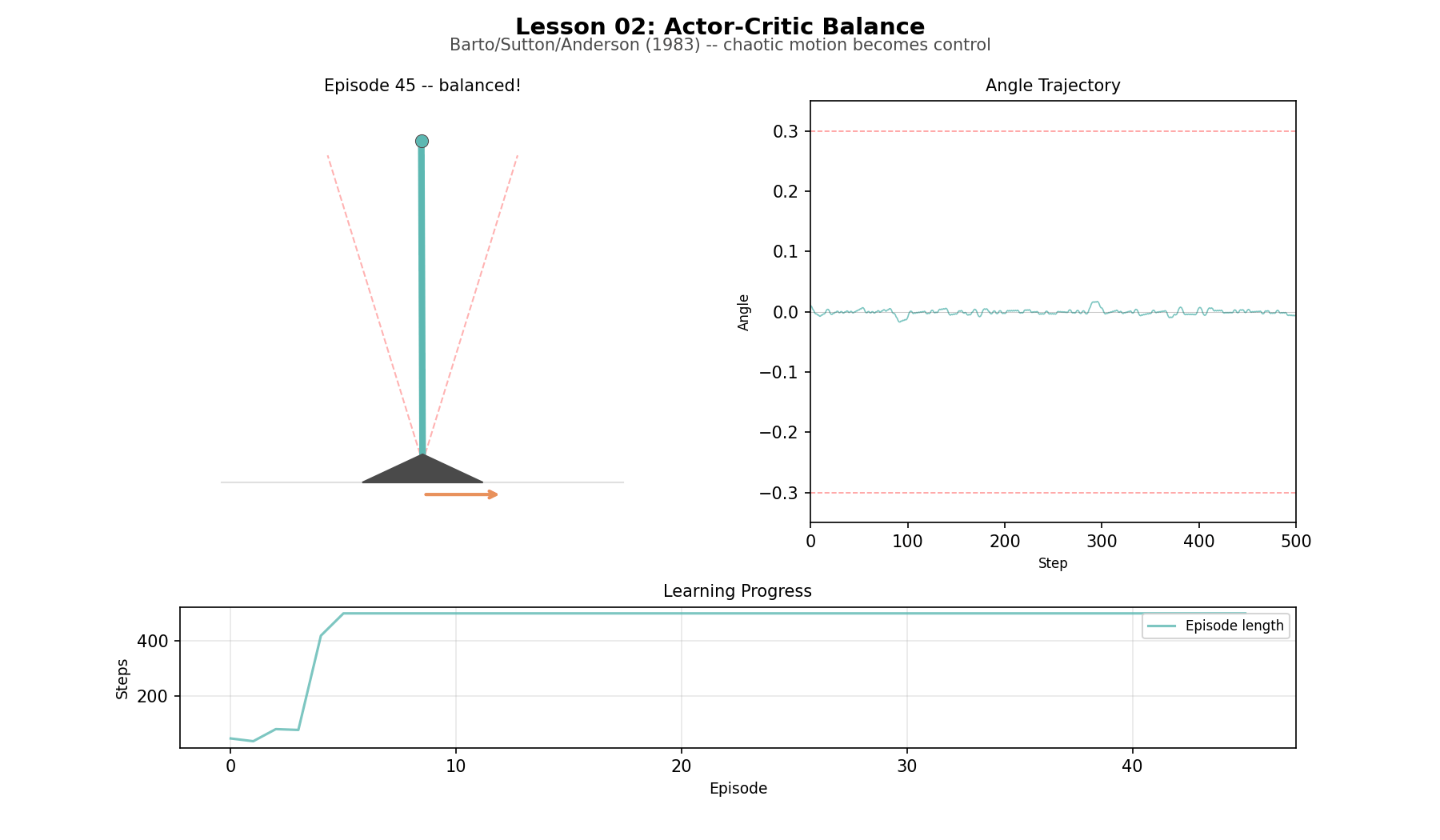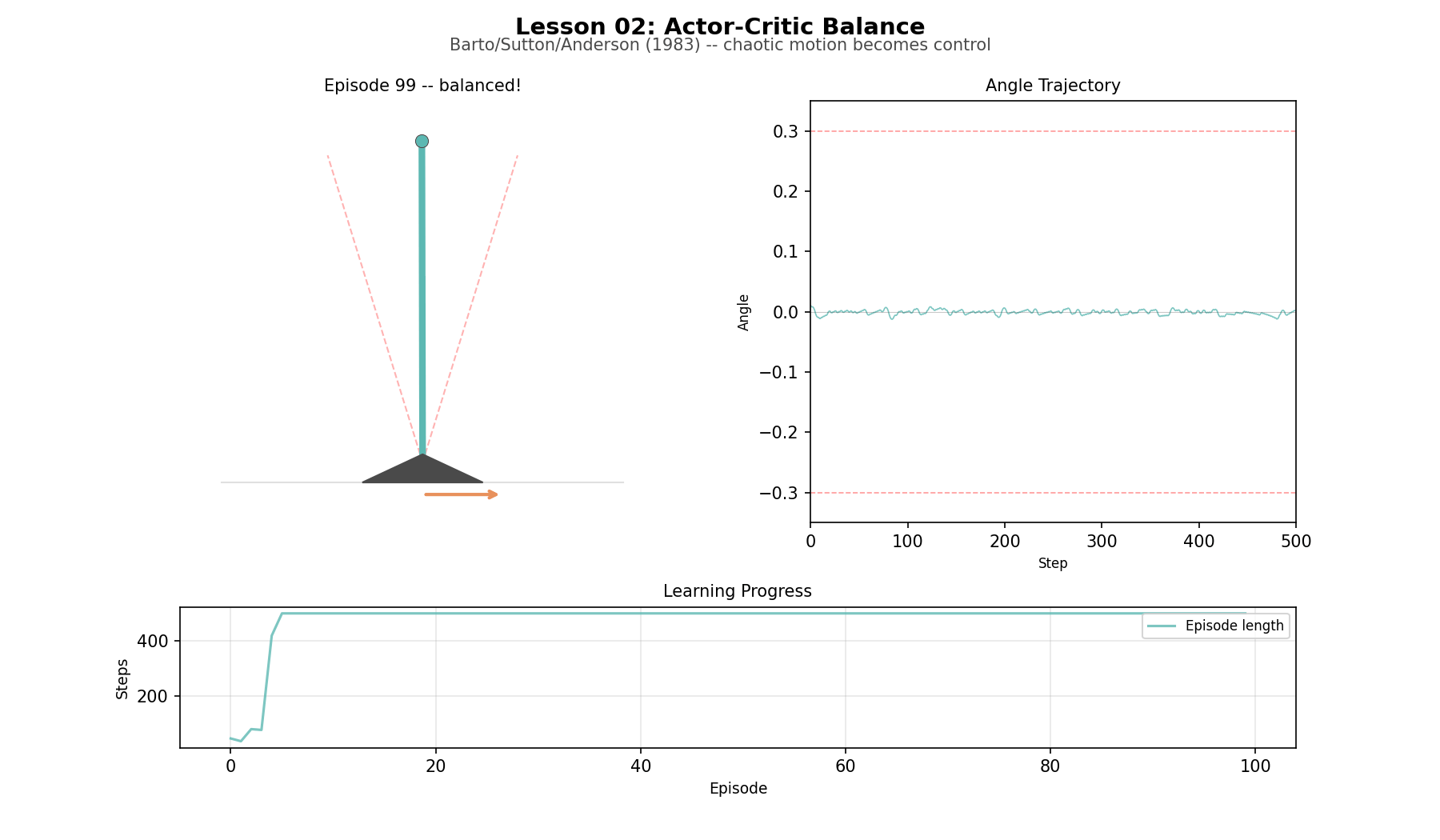
Actor-critic learning to balance
A lot of modern RL looks elaborate, yet every modern policy gradient method—PPO, SAC, A3C—uses an actor and a critic. Building Barto and Sutton’s early control system strips away the embellishments to show the core. The critic predicts. The actor experiments. The temporal difference error nudges both. That basic split survives almost unchanged into modern policy-gradient methods. What changes later is scale, stability, and function approximation, not the underlying division of labor.
3. TD learning works by letting estimates teach estimates
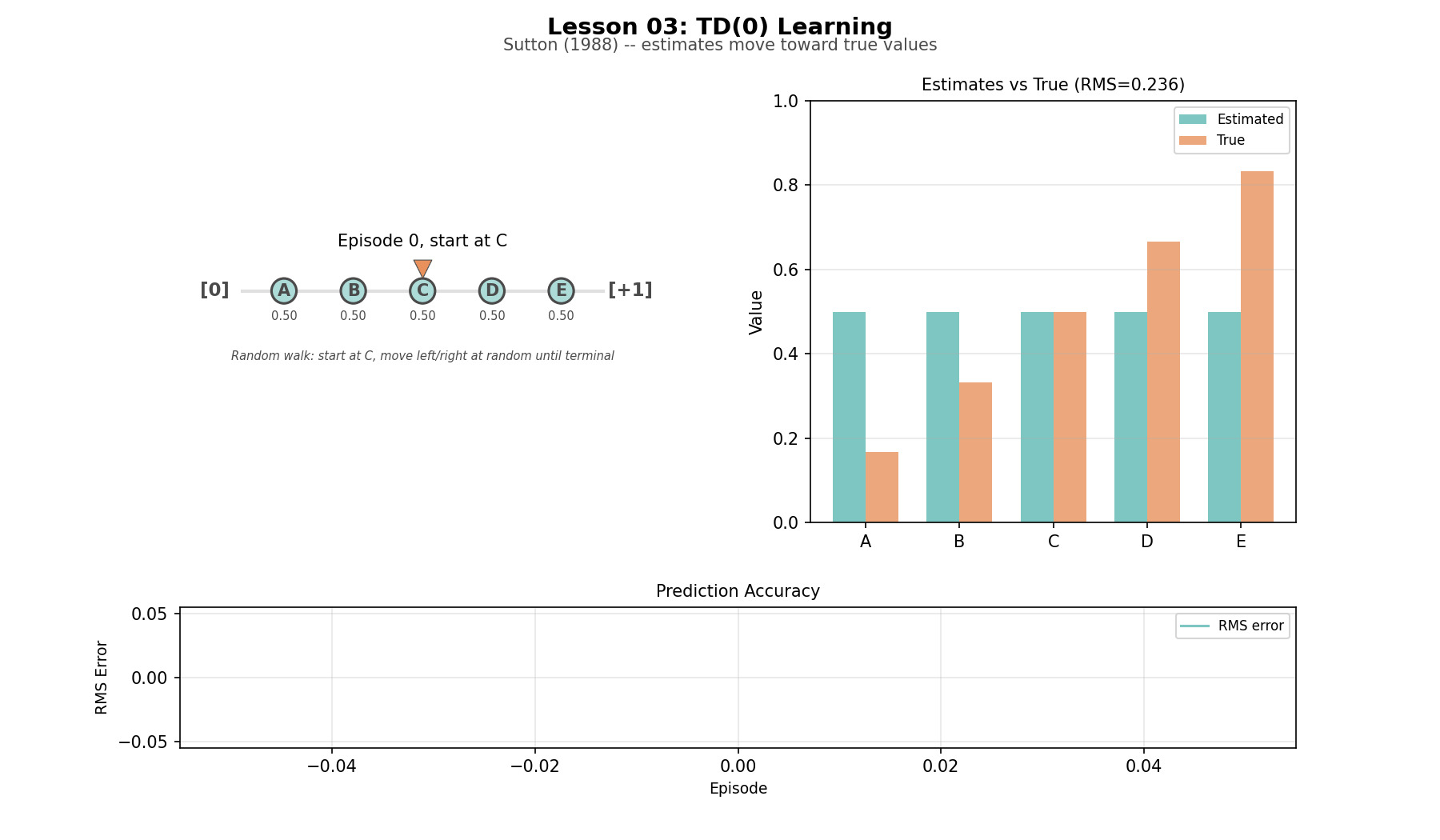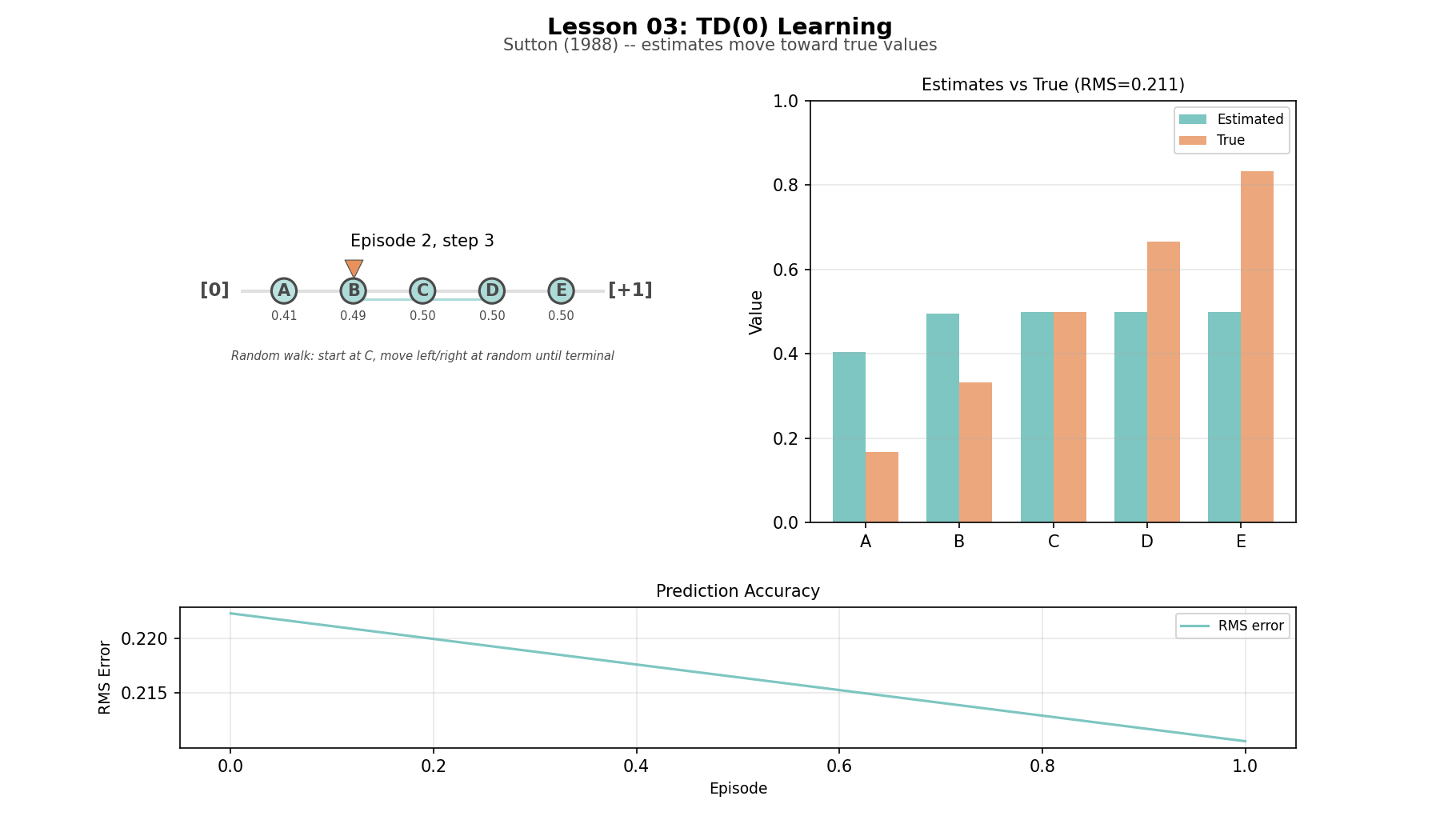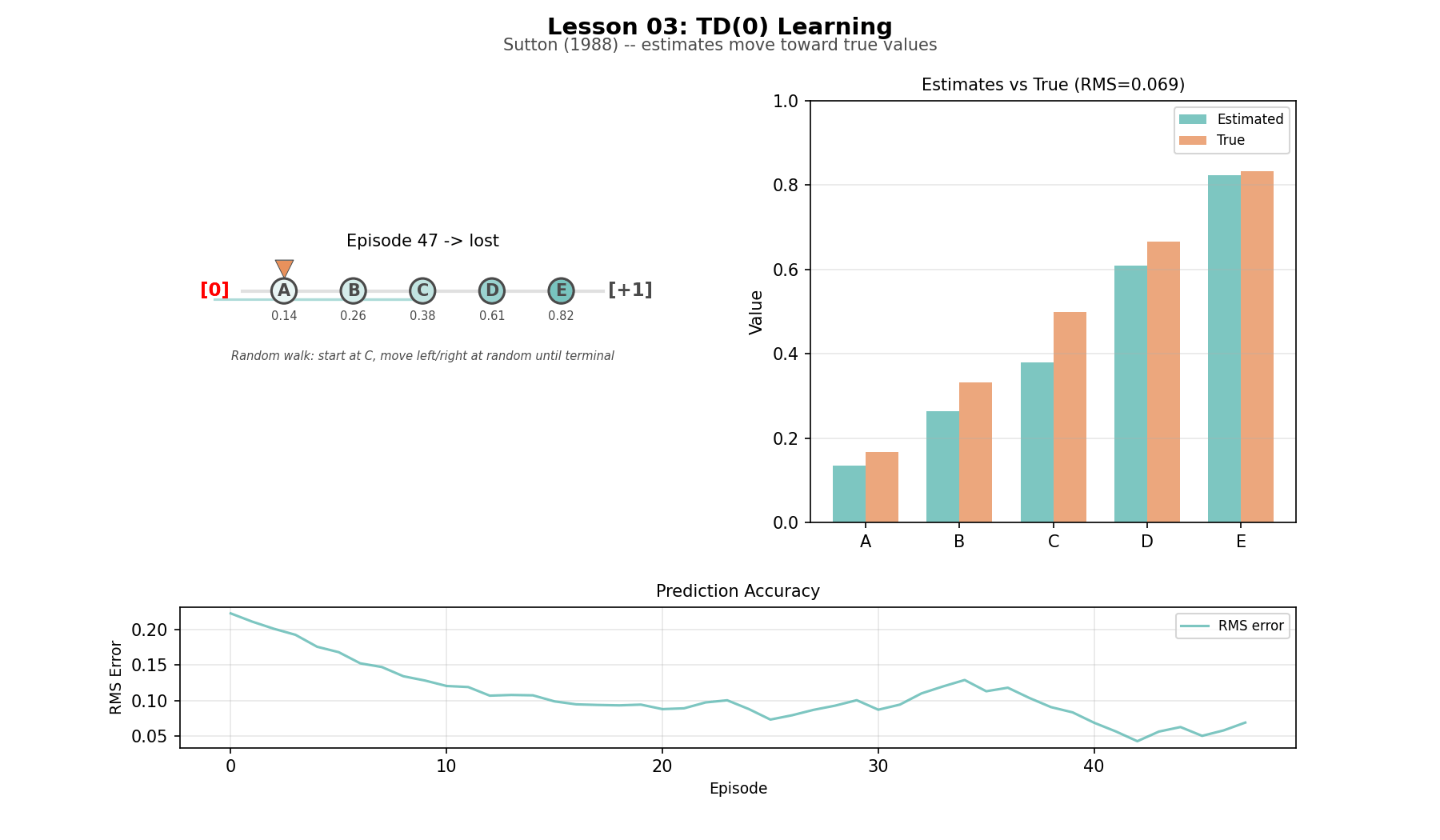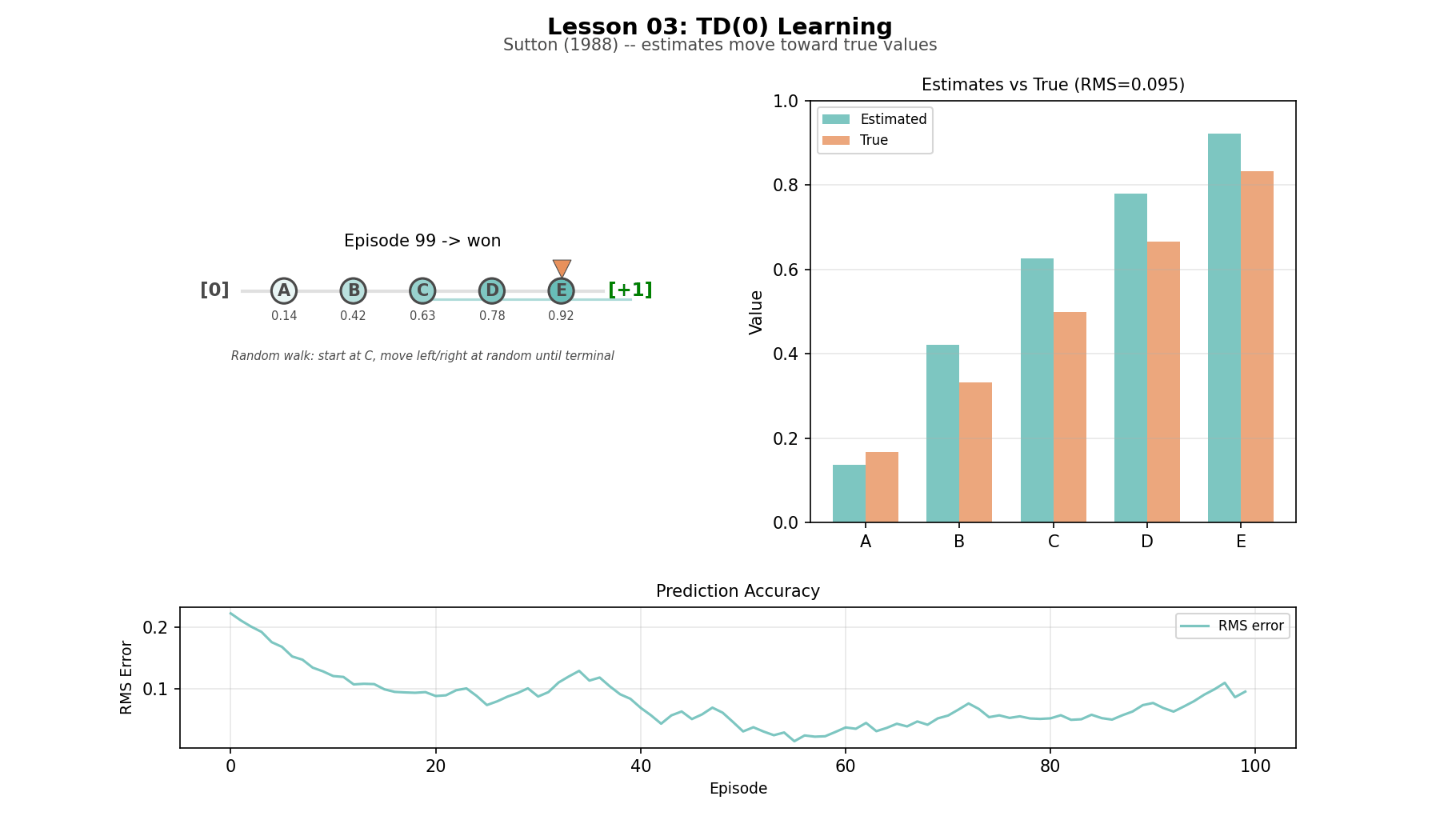
TD learning on the random walk
This is the first idea in the series that felt genuinely strange while building it. In supervised learning, targets come from outside the model. In TD learning, a slightly better guess improves another guess, and the whole chain converges. In the random walk, the estimates do not improve because the agent suddenly sees the whole future. They improve because information leaks backward through successive predictions. That ripple is one of the foundational motions in RL. The whole thing works because a guess based on a slightly-better guess converges to the truth.
4. Q-learning’s max really does split the road in two
Q-learning on the cliff world
The difference between Q-learning and SARSA is easy to write and easy to miss. Q-learning and SARSA use identical code except for one line: Q-learning updates toward max_{a'} Q(s', a'), SARSA updates toward Q(s', a_next).. One updates toward the best possible next action. The other updates toward the action actually taken. On the cliff world, that one-line difference becomes visible in behavior. Q-learning learns the shortest route along the edge. SARSA learns a safer, longer route that accounts for the fact that exploration near the cliff is dangerous. The policy can be better in the limit and worse during training. That trade-off does not show up as philosophy; it shows up in the curve.
The early episodes are useful precisely because they are messy. The first few runs through the cliff world are chaotic. The agent falls repeatedly, restarts, improves, relapses, then improves again. That volatility is not input noise, it is part of the algorithm. Exploration means that even a mostly-correct policy can still do the wrong thing at the worst possible time. Building the system from scratch makes that feel less like a quirk of the benchmark and more like a structural fact about learning from reward.
Building agents with agents
Policywerk was built the same way as modelwerk: with Claude Code, eyes-on and hands-off. I directed the architecture and the layering, reviewed everything, and wrote the lesson narratives. Claude wrote the implementation. The pattern held—set the constraint clearly enough and the agent stays inside it. What worked better this time was the RL-specific code: the update rules, the eligibility traces, the environments. The math is precise enough that correctness is easy to verify and hard to fake. That turns out to be a good fit for the collaboration.
Like we said at the start, these four lessons covered planning, interaction, prediction, control. The ideas are old, but they are still load-bearing. Modern RL systems may have neural networks, replay buffers, target networks, clipped objectives, even latent world models layered on top. Underneath, the same components keep reappearing: value functions, policies, TD errors, and the tension between exploration and exploitation.
The code is slow. The environments are small. The agents are tabular, not neural: that changes in the next three lessons. None of that really matters. What matters is that when the Q-learning agent walks the cliff edge and the SARSA agent takes the safe road, you can open the update function, find the one line that differs, and see exactly why.
In the next post we'll look at the following more advanced and more powerful agents:
Mnih et al. 2013. Playing Atari with Deep Reinforcement Learning.
Schulman et al. 2017. Proximal Policy Optimization Algorithms.
Hafner et al. 2023. Mastering Diverse Domains through World Models.